假设一个电商系统,我们目前有海量的订单信息需要存储在订单表 ( Order ) 中:
| OrderId | UserId | OrderDetails |
|---|---|---|
| 订单 ID ( snowflake 生成 ) | 用户 ID | 订单详情 |
订单表 ( Order )
现在考虑这样一个查询需求:
- 根据
OrderId查询订单详情。 - 根据
UserId查询该用户所有的订单。 - 要求数据库负载均衡,避免单库/单表过载。
在大数据的场景下我们都知道当单表数量达到 2000 万或者 2 GB 的时候就需要进行分库分表。但是所有数据按照指定的分片键进行分库分表后又会产生一个新的问题:如何对非分片键进行查询? 当然我们可以迅速想到一个暴力的方法就是使用多线程同时查找所有的分区,然后再对每个线程的结果进行合并汇总。但是显然这个方案的效率很低。
我们能否直接从非分片键中判断出这条数据在哪个分区呢?答案是:可以的。本文会介绍其中的一种方法:基因法。
假设一个电商系统,我们目前有海量的订单信息需要存储在订单表 ( Order ) 中:
| OrderId | UserId | OrderDetails |
|---|---|---|
| 订单 ID ( snowflake 生成 ) | 用户 ID | 订单详情 |
订单表 ( Order )
现在考虑这样一个查询需求:
OrderId 查询订单详情。UserId 查询该用户所有的订单。假设我们现在需要将订单表分到 16 个表 ( ) 中。
很显然在电商的场景下我们绝大多数的场景是查询某一个 UserId 对应的信息,比如:用户查看自己的订单记录。所以我们首选的是将 UserId 作为分片键进行 Hash 的分区。
当我们需要查找 UserId = 2846741676215238657 的所有订单时,我们只需要对 UserId 进行取模 16 的运算即可知道该用户的所有订单信息所在的分区。2846741676215238657 mod 16 = 7,所以我们可以直接到 中执行以下 SQL 即可取回所有的订单数据。
SELECT OrderId FROM Order_7 WHERE UserId = '2846741676215238657';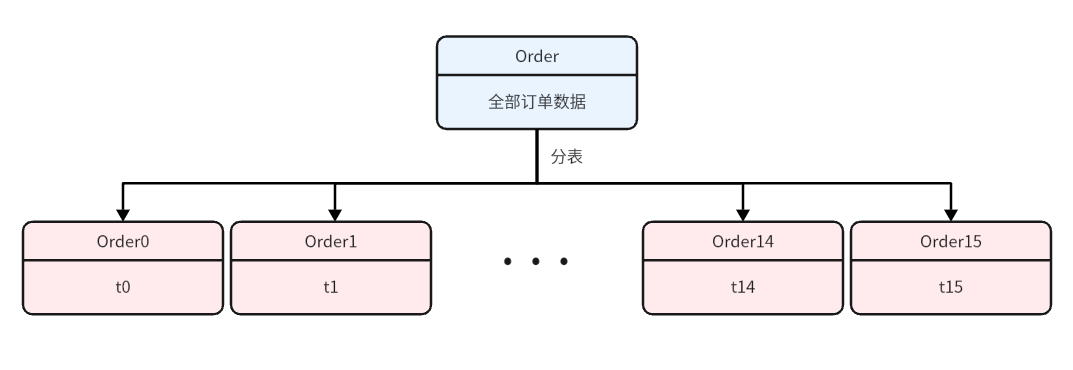
数据倾斜
实际的生产环境中必须小心谨慎地选取分片键,因为不恰当的分片键很有可能导致分表的数据倾斜,即有些表的数据特别多,有些特别少。
这里选用的是 UserId。假设所有的用户都是普通用户,那么每个人的购物数量不会有数量级上的差异。但是如果用 "卖家 ID",那么每个店铺直接的销量差距可能是多个数量级的差距,很有可能会导致严重的数据倾斜。
那么通过 UserId 的取模分片,我们已经将订单数据较为均匀地分散到 16 个表中。其中同一个 UserId 的所有订单都在同一张表中。目前的方案已经满足了本文开头提出的 3 个需求中的 2 个。但是当我们企图根据 OrderId 查询订单详情的时候我们发现,我们无法得知某个 OrderId 在哪个分区中。我们只能遍历 16 个分区,直至找到指定的 OrderId。很显然,这个方法效率是极低的。
这个时候我们自然会想到:如果根据 OrderId 本身就可以直接得知它所在的分区表号就好了。这就涉及到接下来介绍的算法:基因法。我们将 UserId 的片段作为一个基因因子植入 OrderId,以此根据 OrderId 直接获取以 UserId 为分区键所计算的分区。
基因法是基于二进制的一个特性:对于正整数 和 ,取余 的结果等价于保留 的二进制表示的低 位,忽略高位。
假设 ,即二进制为 11101,。 的低 位二进制表示为:101 ( 十进制为 5 ) 。而 29 mod 8 = 5,刚好和低 3 位的二进制表示相同。
所以我们可以得知,当两个数值的二进制表示中的低 位相同时,其对 的取模结果也相同。所以当我们使用 UserId 将数据分到 16 个表中的时候,决定每个 UserId 的分区号实际上是其低 4 位 ( ) 的二进制。
基于上述的理论基础,我们现在来使用基因法生成我们需要的 OrderId,让其本身就能计算出来 UserId 的分片信息。
生成唯一 ID。
使用雪花算法 ( snowflake ) 生成一个 64 bit 的分布式唯一 ID。
计算出分片基因。
分片键是 UserId,一共分 16 个表,所以分片基因是 UserId 的低 4 位。例如 2846741676215238657 的二进制低 4 位是 1001,所以其分片基因是 1001.
将分片基因替换雪花算法生成 ID 的低位。
将 snowflake 生成的 ID 的最后四位直接改为分片基因。
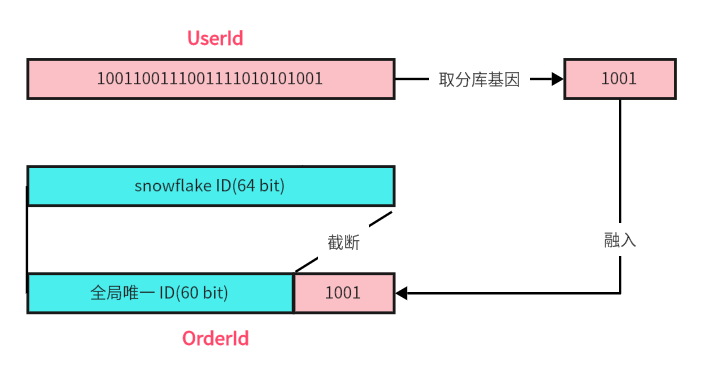
这样生成的 OrderId 可以保证当 UserId 相同的时候,OrderId 也会被分到同一个分区,因为其低位被替换成相同的二进制了。
可能出现重复 ID
这种基因替换法在极端的情况下无法保证 ID 一定不重复。因为假设在同一个用户在一毫秒内创建了 2 个订单,那么雪花算法生成的 ID 的高位就是一样的,只有低位相差 1. 然而在基因替换法中我们又将这两个 ID 的低位替换成了同一个 UserId 的固定低位。这会导致这两个 ID 变得完全一样。
这种现象非常极端,手动操作下几乎不可能出现,但是不排除脚本刷单时出现该状况的可能性。
为了避免 OrderId 重复的问题,我们也可以将 "替换法" 改为 "拼接法"。在构建 OrderId 的时候直接将分片基因拼接在生成的 ID 后面,即 OrderId = string ( snowflakeId + UserId )。
但是这样可能会导致 ID 的长度非常大。所以我们也可以只拼接 UserId 的最后 4 位或 6 位。事实上,淘宝的订单编号就是这样生成的。同一个用户的订单最后 6 位是相同的。这意味着淘宝将其分为了 个分区。
基因拼接法是基于十进制的字符串进行拼接,而基因替换法是基于二进制的。
本文主要介绍了基因法这种算法来解决分表情况下对非分片键的查询优化问题。而基因法又分为:
拓展阅读
在分表的时候我们通过基因法可以将数据分到指定数量的分区中。但是如果数据量不断增长,原本的分表数量变得不足以支撑业务时,我们可能会面临分表的数量增加的情况。
分区数量的增加意味着原先按照 Hash 取模运算进行的分区会产生变动,这可能涉及到大量的数据迁移。而数据迁移不仅仅耗费资源,而且还可能导致系统的不可用以及增加额外的网络压力。针对于这个问题,我们可以通过 一致性 Hash 算法 来解决。
