记一次 RocketMQ 消息重复的排查
2025 年的最后一天,记录一下今年遇到的一个 RocketMQ 重复投递消息的问题。本质上是对 Consumer 参数设置的不正确所导致的。

MySQL 联合索引创建指南
实际的开发过程当中为 MySQL 建立联合索引是无法避免的。但是考虑到最左匹配原则和一些索引失效的场景,建立索引仍然存在一些技巧。本文将给出一些简单的场景,根据这些场景来讨论如何创建 MySQL 联合索引是最有效的。

MySQL 什么情况下会索引失效?
在 MySQL 中建立索引来提高查询效率是人尽皆知的事情,但是并非所有的索引都会生效,根据不同的查询场景建立不同的索引是每个工程师必须掌握的技能。
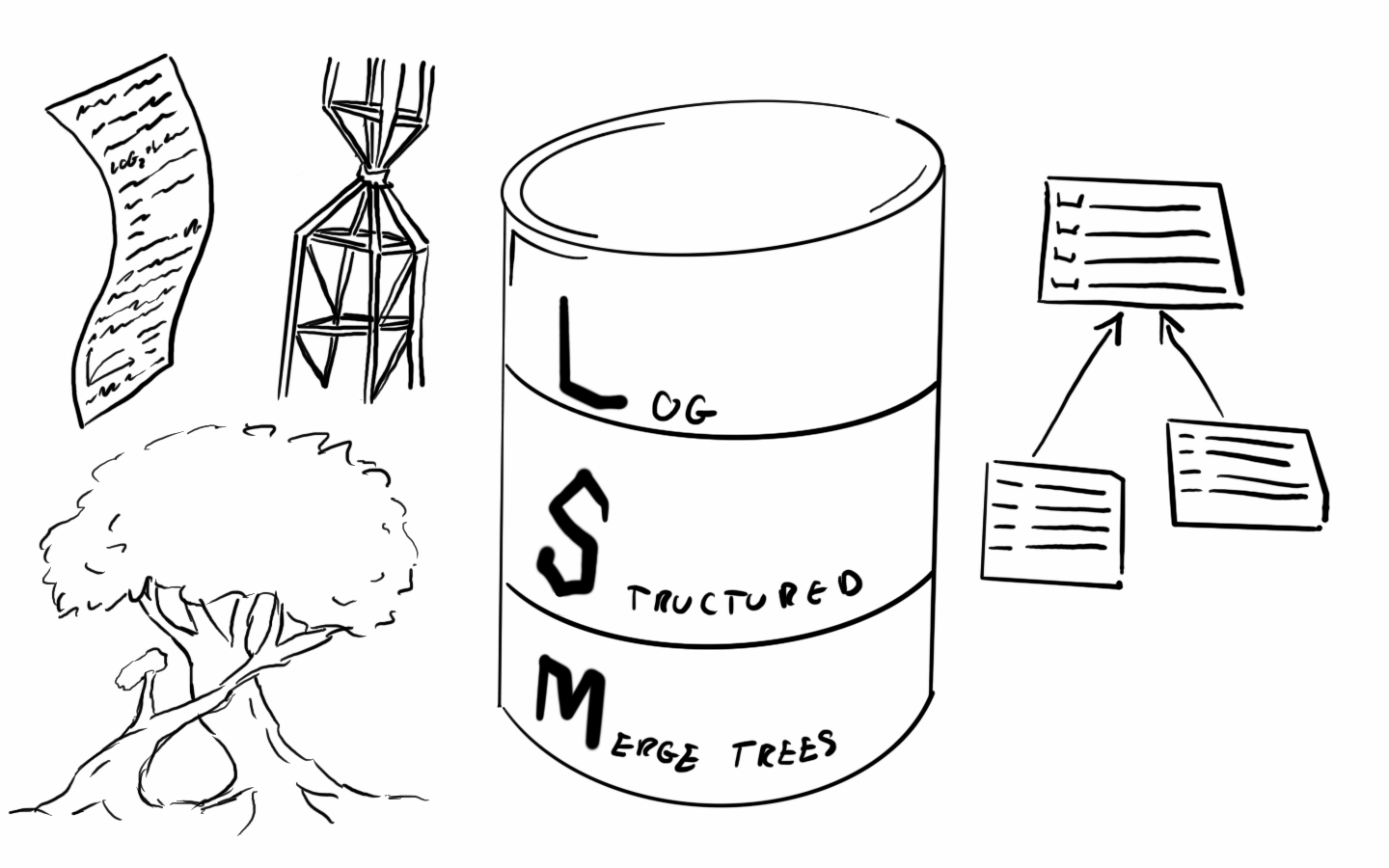
LSM-Tree:一文了解 NoSQL 存储系统的核心的增删查改
如果你曾经接触过 NoSQL 数据库,例如:HBase、LevelDB、RocksDB,那么你应该就听说过 LSM 树。大多数的 NoSQL 数据库的底层都有 LSM 树的身影。LSM 树的概念来自于一篇论文:《The Log-Structured Merge-Tree ( LSM-Tree ) 》,今天我们就来讨论一下 LSM 树的原理以及它是如何增删查改和合并数据的。

后端如何安全地存储用户密码?加盐!
几乎所有的系统都需要用户进行注册和登录操作,其中最常见的登录方式就是让用户输入用户名和密码。早期的许多系统就仅需要用户名和密码即可登录,但是有一些网站就遭遇了暴力破解、社工破解 指通过操纵人类心理而非技术手段来获取密码或敏感信息的攻击方法。其核心在于利用人性的弱点,如信任、恐惧、好奇或疏忽,诱使目标主动泄露信息或执行特定操作。 指数据库的数据被攻击者直接导出。

如何在高并发下减扣库存?
这是一个电商的常见场景,目前互联网大厂对其都有非常成熟的解决方案。我写这篇文章只是给出一些我自己的思考。
MySQL 数据库的 MVCC 机制
MySQL 作为一个多线程的数据库,支持客户端对其的并发查询,并且将其默认的隔离级设置为可重复读。那么在并发的操作中 MySQL 是如何隔离各个事务的呢?它实际上使用的是

在保证分布式事务一致性的过程中我们会遇到什么问题?
在微服务架构盛行的今天,如何保证分布式事务的一致性是每一个后台开发工程师都可能遇到的问题。
分布式节点个数为什么通常是奇数个?
作为一名研发工程师,在我的日常工作中经常涉及到各种分布式系统,例如:ETCD, Redis, k8s 等。这些分布式集群在部署的时候我们通常将节点的数量设置为奇数个,这似乎是一个约定俗成的规则。但是为什么?除了偶数节点容易出现投票平票的情况是否还有其他的原因?