Understanding the Raft Algorithm: Detailed Explanation of Consistency and Leader Election Mechanism
In a distributed system, there are usually many nodes. If the nodes need to reach a consensus, ensuring the consistency between the nodes has become a concern for all distributed systems.
Raft is a very classic distributed algorithm that can ensure that all nodes in a distributed system maintain a continuous consistency state. It is a consistency algorithm for managing replication logs. The Raft algorithm aims to coordinate the operation of all nodes by providing fault tolerance and ensuring the election of a single leader. In this article, we will delve into the core concepts of the Raft algorithm, focusing on node consistency and the election of leader nodes.
What is the Raft algorithm?
The Raft algorithm was first proposed by Diego Ongaro and John Ousterhout of Stanford University. In order to better understand the previous distributed consistency algorithms, such as: Paxos provides better fault tolerance and leader election capabilities.
Quick connection
So what is a consistency algorithm? Why do we need it?
The consistency algorithm is mainly used to solve the fault tolerance problem in distributed systems. If all information is stored on one node in the cluster, then when this node goes down, the cluster will not be able to respond to client requests and information may be lost. So in order to solve this problem, we hope that all nodes in the cluster will save the same information, so that even if one of the nodes goes down, the other nodes can still fulfill the same obligations and respond to requests. So how to make all nodes in the cluster consistent? The usual practice is to use replication log. Each node has a set of logs, which contain the same order of execution commands, so the final effect after execution is the same. The goal of the consistency algorithm is to achieve consistency of the replication log.
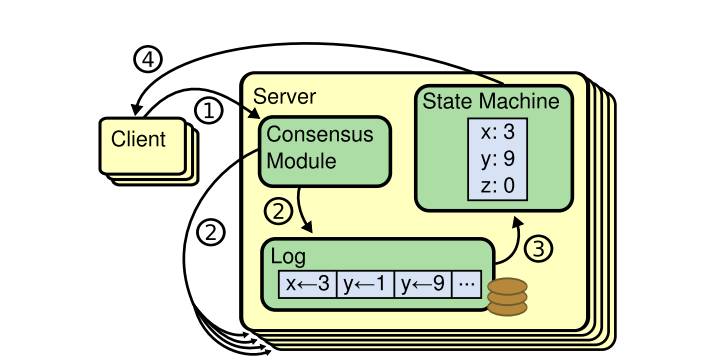
In this replication state machine architecture diagram, we can see:
- The client sent a request.
- The consensus algorithm generates a log for the three operations on the data in the request: , , .
- The state machine modifies the data according to the log.
- Return the modified result to the client.
Core concepts
Note
In order to avoid ambiguity and align with the paper, English words are used here, but Chinese explanations are attached. These key concepts are also in English in the following text.
- Node: Node. In Raft, a network cluster is composed of multiple nodes or servers.
- Leader: Leader. In a Raft cluster, one of the nodes will be elected as the Leader. The Leader will be responsible for managing the log replication of all nodes in the cluster.
- Follower: Follower. All nodes in the cluster except the Leader are Followers. They will respond to the Leader Request and forward the client's request to the Leader.
- Candidate: Candidate. When the Leader goes down, the cluster needs to elect a new Leader. The node will change its identity to Candidate and start the election.
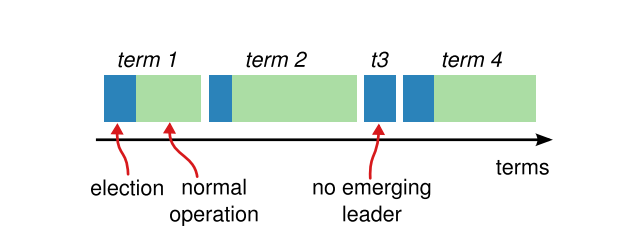
- Term: Term. The Raft algorithm uses Term as the cycle. Each Term starts with an election and ends when the next new Leader is elected or re-elected.
- Log Replication: Log replication. The Raft algorithm ensures that all logs in the cluster are replicated and saved in the same order.
- RequestVote RPC: Initiated by Candidate during the election.
- Append-Entries RPC: Initiated by Leader, used to copy log entries and provide a form of Heartbeat.
- SnapShoot RPC: Used when transmitting node snapshots.
Raft process
The Raft algorithm is mainly divided into three problems:
- Leader election. When the existing Leader goes down, a new one needs to be selected Leader
- Log replication. The leader node accepts client requests, writes logs, and manages other nodes to make them consistent with its own logs.
- Safety.
- Election safety. There is at most one Leader.
- Logs are append-only.
- Log matching. If two logs contain entries with the same index and term, then the logs of all entries starting from a given index are the same.
- Leader integrity. If a log entry is submitted in a given term, then this entry will appear in the logs of all leaders with higher-numbered terms.
- State machine safety. If a log entry with a given index is applied to the state machine of a node, then other nodes will not apply different log entries for the same index.
Raft will first select a Leader in the cluster, and then this Leader node will be fully responsible for the implementation of consistency. The Leader will accept client requests, generate log entries for related data operations, notify the remaining nodes to copy these log entries, and after the copy is completed, tell other nodes when it is safe to apply the log entries to their state machines.
As you can see, Leader is Raft The key to simplifying log replication management in the algorithm. Data flows from the Leader to other nodes in a simple way, and synchronization consistency can be achieved by simply copying the log.
Leader election
Raft nodes have three states: Follower, Candidate, Leader.
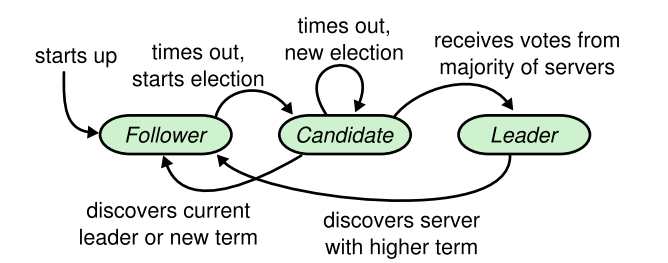
From the state transition diagram, we can see that at the beginning, all nodes are Followers. If they do not receive the heartbeat of the Leader for a period of time, they will be transformed into Candidates to participate in the election. If they get the votes of most nodes, they will become the new Leader. If other nodes become the new Leader first, they will degenerate into Followers.
Election process
At the beginning of each term, all nodes are Followers.
If a Follower does not receive any information sent by the Leader within a cycle ( the election expires ) , it will be transformed into a Candidate.
Candidate It will ask other nodes to vote for it. If it receives more than half of the votes, it will become the Leader.
If no Node successfully receives more than half of the votes, a new election will be launched in the next Term.
Log Replication
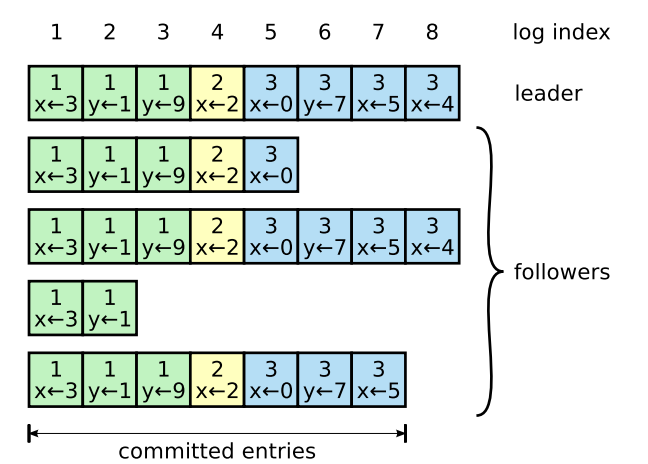
From the above diagram, we can see that each log entry contains two pieces of information: The command that the state machine needs to execute and The Term to which the log entry belongs. All the logs in the figure are divided into 3 Term, marked in green, yellow and blue respectively. Each Term represents a new Leader. The number of the Follower's log will be less than or equal to the Leader, depending on its synchronization progress. The bottom of the figure shows committed entries, which means that the entries numbered 1-7 have been committed to the state machine, and the Leader will think that index = 7 The log is "safe".
Log replication process
Leader accepts the client's request and appends it to its log as a new log entry.
Leader concurrently sends AppendEntries RPC requests to all Followers, asking them to replicate the entry.
Followers reply to Leader to confirm the replication after successful replication.
Once more than half of Followers confirm the request, Leader applies the log entry to its state machine and replies to the client that the message is received successfully.
Normally, the logs of Leader and Follower will be consistent, but the crash of Leader may cause log inconsistencies, which may be aggravated in a series of Leader and Follower crashes.
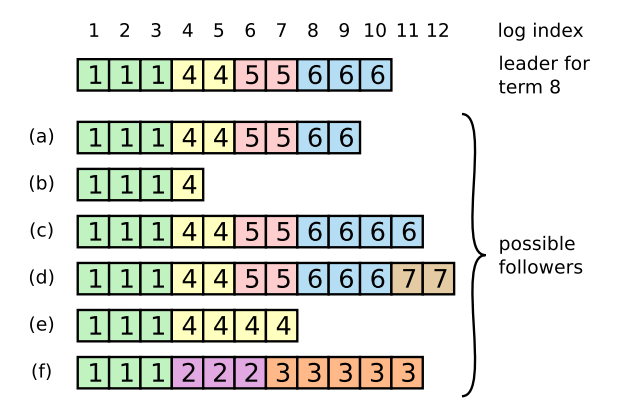
When the node in the first row of the figure becomes the new Leader in the 8th term , the Follower log may be any of ( a-f ) . ( Again, each box represents a log entry; the number in the box is its item )
A Follower may be missing entries. For example, examples ( a - b ) .
There may be additional uncommitted entries. For example, examples ( c-d ) .
Or both. For example, examples ( e-f ) .
For example, scenario ( f ) may occur for this reason: If the node is the leader of Term 2, adds a few entries to its log, and then crashes before committing any entries. It quickly restarts, becomes the leader of Term 3, and adds more entries to its log. Before committing any entries in Term 2 or Term 3, the node crashes again and remains down for the next few terms.
Given the above scenarios, the Raft leader will force the follower to synchronize its log. This means that the conflicting log entries in the follower will be forcibly overwritten by the leader's log.
- So how does the leader make the follower How to force synchronization with itself?
The Leader must find the last log entry that both parties agree on between itself and the Follower, delete all logs after that entry in the Follower, and then send all logs after its own entry to the Follower. All these operations are responses to the consistency check performed by the AppendEntries RPC.
- So how does the Leader find the last non-conflicting log entry between itself and the Follower?
The Leader will save the nextIndex corresponding to each Follower. This index represents the log that the next Leader will send to this Follower. When a new Leader is just elected, it will initialize the nextIndex value of all Followers to the next index value of its last log ( the value is 11 in Figure 5 ) . If a Follower's log is inconsistent with the Leader's log, it will fail the AppendEntires consistency check in the next AppendEntries RPC. After being rejected, the Leader will use trial and error, that is, decrement nextIndex 's value and retries the AppendEntries RPC. Eventually nextIndex will reach the latest point where the Leader and Follower logs match. At this point, AppendEntries will succeed, and then delete all conflicting parts of the Follower log and append the Leader's log after the latest point ( if any ) . Once AppendEntries succeeds, Follower and the Leader's logs are consistent, and it will maintain this processing mode for the rest of the term.
Security
In the previous chapter, we described how Raft elects the Leader node and replicates the log entries. However, the mechanism described so far is not enough to ensure that each state machine executes the same commands in the same order. Some restrictions will be given below to ensure strong consistency.
Election restrictions
The consistency algorithm needs to ensure that the Follower with the latest log entry can be elected as the Leader. Raft uses a very simple mechanism that ensures that from the moment of election, each new Leader has all the entries submitted in the previous term. Instead of the new Leader itself needing to synchronize these entries. This means that there is only one direction of log flow in the cluster: Leader Follower.
This mechanism mainly uses RequestVote RPC. If the voter's own log is newer than the Candidate's log, the voter refuses to vote. Raft determines which of the two logs is newer by comparing the index of the last entry in the log and the term. First compare the term, the later term log is newer. If the terms are the same, The log with a larger index is updated.
Commit log entries from previous terms
Is it safe when we ensure that the new leader has the latest log during the election? Obviously not.
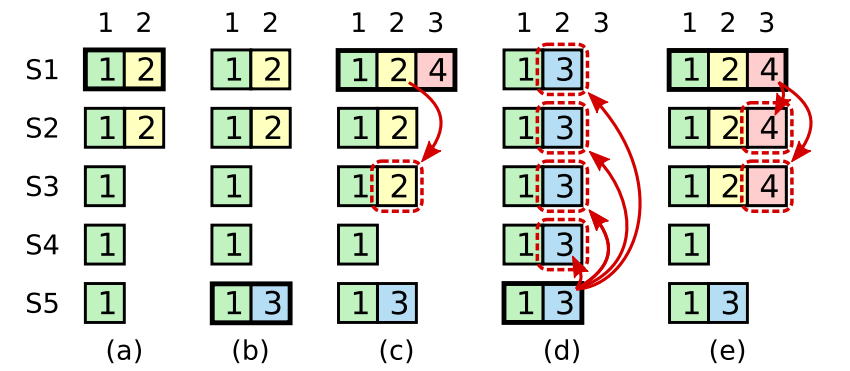
Let's consider the example in the figure above:
- ( a ) : S1 is elected as the leader and synchronizes the log of Term 2 ( yellow ) to S2.
- ( b ) : S1 is offline, and S5 becomes the new leader of Term 3 in Term 3 and appends a log ( blue ) .
- ( c ) : S5 is offline. S1 recovers and becomes the leader again, and continues log synchronization. At this time, most followers have synchronized S1's Term 2, but have not submitted it.
- ( d ) : S1 is offline again, S5 becomes the leader again ( receives votes from S2, S3 and S4 ) , And force other nodes to synchronize their own Term 3 logs ( blue ) .
- ( e ) : If most nodes replicate the current term entry before S1 goes offline, such as ( e ) , the red entry is submitted ( S5 cannot win the election ) . At this time, all log entries before the red entry are also submitted.
The above situation shows that when submitted according to the principle of majority Follower synchronization, although the old log is placed on most nodes, it will be overwritten.
So before submitting log entries, you should wait until there is a Leader entry for the current term submitted, and then submit all previous entries together.
Follower and Candidate crashes
- If a Follower or Candidate crashes, the RequestVote and AppendEntries RPCs sent to it will fail.
- Raft handles these failures by infinite retries. If the crashed server restarts, the RPC will complete successfully. If the server crashes after completing the RPC but before responding, it will receive the same RPC again after restarting.
- If a Follower receives an AppendEntries Request, which contains log entries that already exist in its log, it will ignore those entries in the new request. That is, RPC in Raft is idempotent.
Time and availability
The following formula must be satisfied to select the leader:
- broadcastTime: The average time required for a node to send RPCs to each node in the cluster in parallel and receive responses. 0.5 ms - 20 ms.
- electionTimeout: election timeout. 10 ms - 500 ms.
- MTBF: The average time between failures of a single node. It may be as long as several months.
Summary
Node consensus in Raft
The method of reaching consensus in Raft is critical to ensuring the integrity and consistency of distributed systems. Consensus is reached through a series of steps:
- Leader election:
- If the leader fails, the peer node will monitor the synchronization request from the leader within the set threshold. If this threshold is exceeded, The peer node will consider the leader unavailable and trigger a leader election. It will request votes from other nodes and declare itself the new leader after obtaining a majority.
- Each node will randomly set its threshold to prevent simultaneous elections. This threshold must exceed the synchronization interval to prevent the election from being triggered when the leader is not down.
- Log replication
- When a client initiates an operation, such as inserting a key-value pair, the leader node will receive the request.
- The leader appends the operation to its log and broadcasts this log entry to all other nodes in the cluster.
- Each node in the cluster will append this request to its own log.
- Majority agreement
- Raft operates on the principle of majority agreement. The leader will wait for confirmation from the majority of nodes before submitting an operation to its state machine.
- If most nodes ( e.g. ) have copied the operation in their logs, they are considered to have confirmed the operation, and the leader submits the operation to its state machine.
- This ensures that the operation officially becomes part of the system state and will be applied consistently across all nodes.
In addition, the Leader periodically sends updates to other servers to keep them in sync. This ensures that even if a server falls behind or crashes, it can quickly catch up to the latest state of the key-value store.
Synchronizing with peer nodes
Synchronizing with peer nodes is a key aspect of Raft's design, which maintains consistency and enables new nodes to join quickly. Here's how it works:
- New server synchronization
- When a new server joins the Raft cluster, it needs to quickly become consistent with the current key-value store.
- To accomplish this goal, the Leader sends a series of log messages to the new server to ensure that it has a complete log backup.
- These logs will contain all previous data operations.
- Determine synchronization logs
- The Leader determines which logs to send for the synchronization process based on the last confirmed log index of each peer node.
- If the peer node has confirmed the log at index , the Leader will send to the last log ( n ) starting from index for synchronization.
- This process ensures that the new server receives all the operations it missed and keeps it consistent with the latest state of the key-value store.
- Handling Sync Errors
- If the leader does not know the last confirmed log index of the peer node, it will use trial and error.
- The leader starts at the end of its log index and decreases the index based on the response of the peer node.
- If the peer node does not have the log before sending the index as part of the sync request, it will return an error.
This iterative process ensures that the new server receives the correct log for synchronization.
References for this article
- Understanding Raft Algorithm: Consensus and Leader Election Explained
- The Raft Consensus Algorithm
- [【6.824] 10,000-word explanation of the Raft consensus algorithm]( https://zhuanlan.zhihu.com/p/522435604 )
- In Search of an Understandable Consensus Algorithm ( Extended Version ) ( All screenshots in the article are from this paper )
Contributors

Changelog
Copyright
Copyright Ownership:dingyuqi
License under:Attribution-NonCommercial-NoDerivatives 4.0 International (CC-BY-NC-ND-4.0)