What problems will we encounter in the process of ensuring the consistency of distributed transactions?
In today's microservice architecture, how to ensure the consistency of distributed transactions is a problem that every backend development engineer may encounter.
Although there are very mature solutions for the consistency of distributed transactions ( for example: 2PC, 3PC, TCC, etc. ) , I found that there are few articles explaining the problems that may be encountered, that is, the defects of each solution. In fact, these defects are exactly what engineers must pay attention to, which is related to the stability of the system and the problems you may encounter in the production environment.
This article will introduce each solution in a relatively simple language, and then focus on their defects and how to improve them.
Why do we need distributed transactions?
In the database, we call an operation consisting of one or a group of SQLs a transaction, and each transaction is either completely successful or completely failed. All of this is usually guaranteed by the database itself. Common relational databases such as MySQL and PostgreSQL will guarantee the atomicity of transactions.
However, in the microservice architecture, all business data is not stored in the same subservice, that is, the data is not in the same database cluster. At this time, the database can only guarantee the atomicity of its own transactions, but cannot control the transaction operations of the database in another server. This kind of transaction involving the operation of two different subservice databases in the same business operation is called a distributed transaction. And because distributed transactions involve multiple independent databases, data inconsistencies between different databases may occur due to partial operation failures during the operation.
For example, we now have an e-commerce system, which contains two subservices: Inventory Management and Order System. When a user makes an "order" business operation, the inventory management service needs to reduce the inventory of the product by one, and the order system needs to generate new order information. At this time, if the order information is generated successfully, but the operation of reducing the inventory by one fails due to network or other factors, the inconsistency of distributed transactions will occur.
The following content of this article will introduce methods to solve this inconsistency and the disadvantages of these methods.
2PC
Algorithm principle
2PC is also known as: two-phase commit. That is, the commit of a distributed transaction is divided into two stages: Prepare and Commit. There are two roles in the whole system: a coordinator and several participants. The coordinator is responsible for publishing transactions and controlling the stages of the algorithm. The participants are responsible for executing specific SQL transactions and feeding back the execution results to the coordinator.
Let's now take a look at what the coordinator and participants do in the two stages.
Prepare
When we start a distributed transaction, the 2PC algorithm will enter the Prepare stage, and all participants will try to execute this transaction locally.
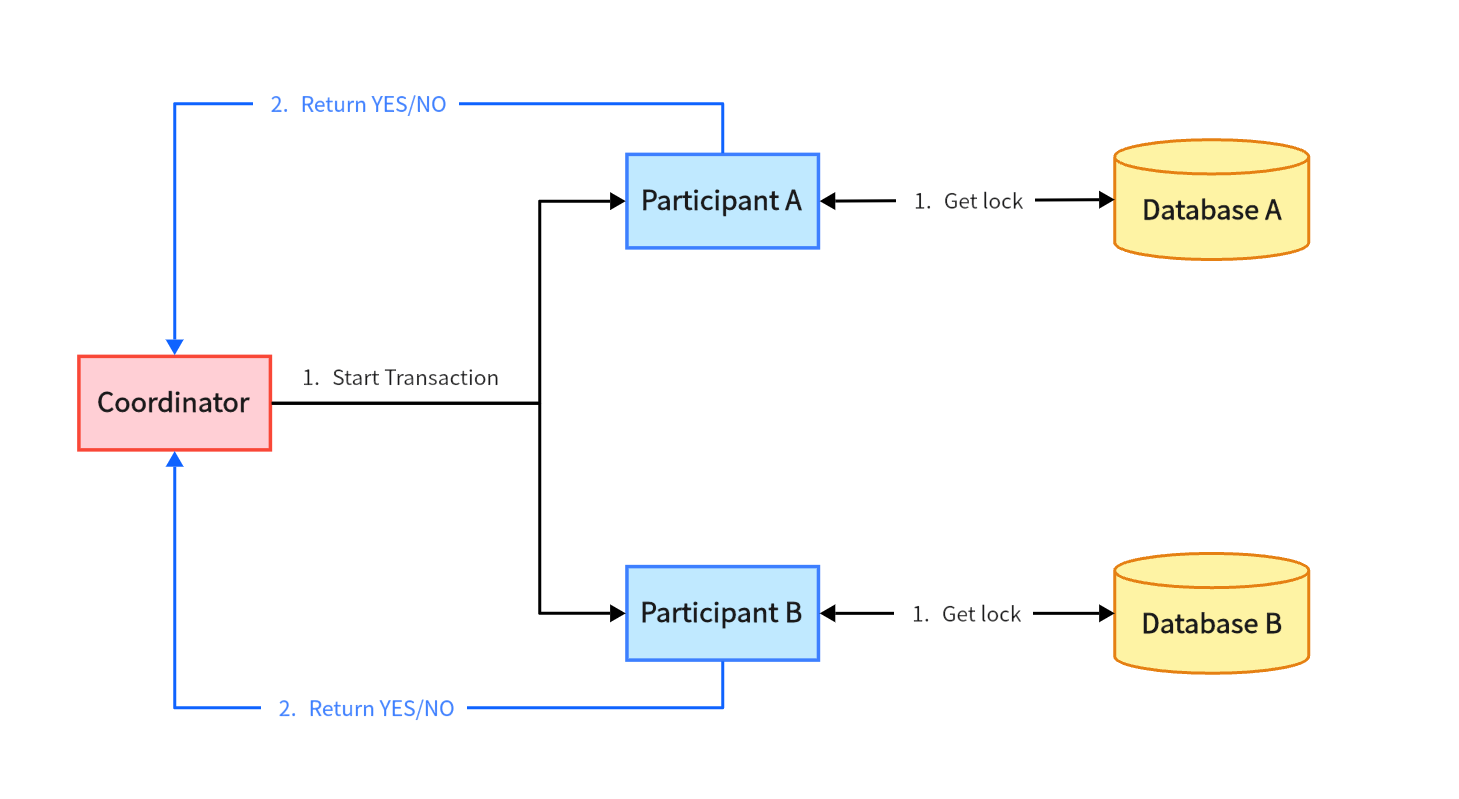
The coordinator issues transaction commands to all participants.
The participants lock resources and pre-execute commands.
Return the execution result to the coordinator. The returned result may be success or failure.
Commit
When the first phase Prepare ends, the coordinator will receive feedback from all participants, that is, whether their own local transactions are executed successfully. At this time, the coordinator will issue the Commit phase command based on all these feedback information. If all participants are successful, the commit command is issued to let all participants formally commit their local transactions. If any participant fails to execute, the rollback rollback command is issued to let all participants abandon the transactions that have been executed locally and roll back the data to the state before the entire distributed transaction started.
The coordinator checks the feedback information of all participants.
If all are successful, the
commitcommand is issued to all participants.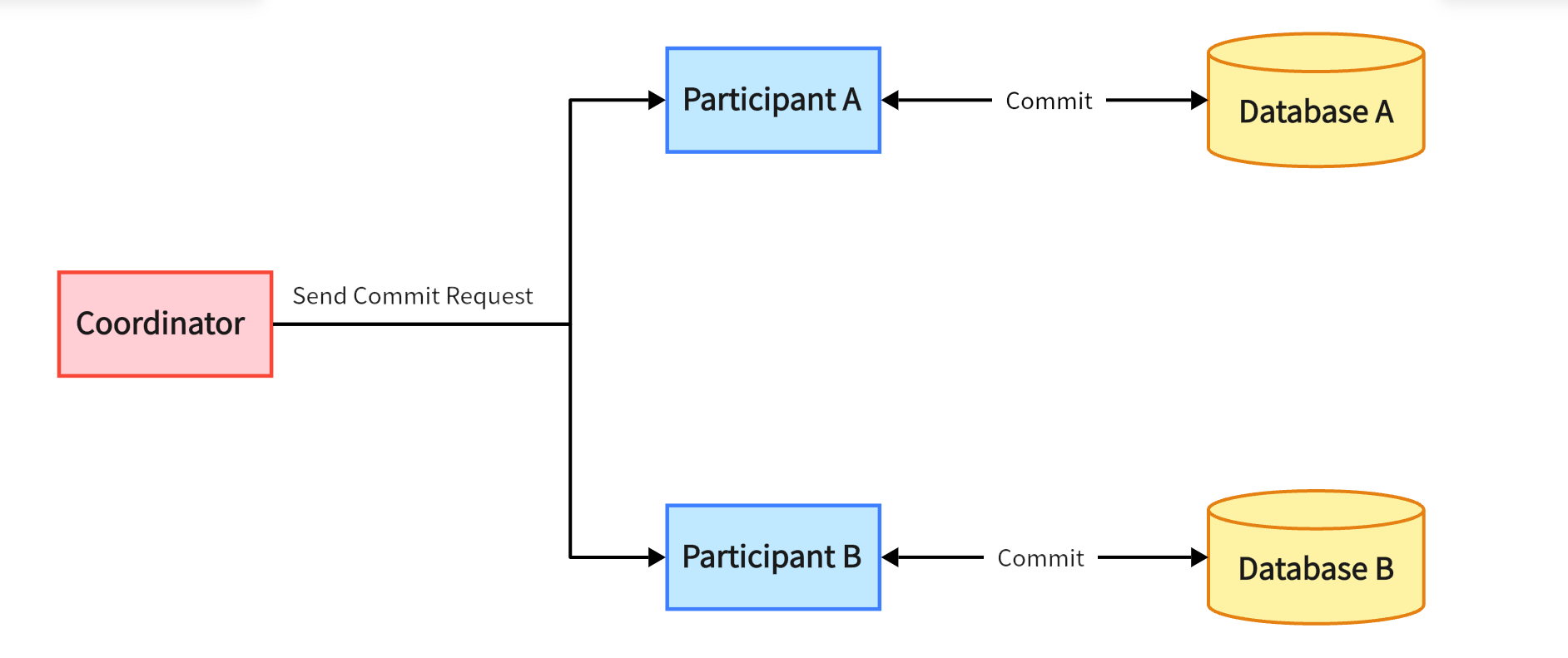
2PC Commit Phase - commit If any participant fails, the
rollbackcommand is issued to all participants.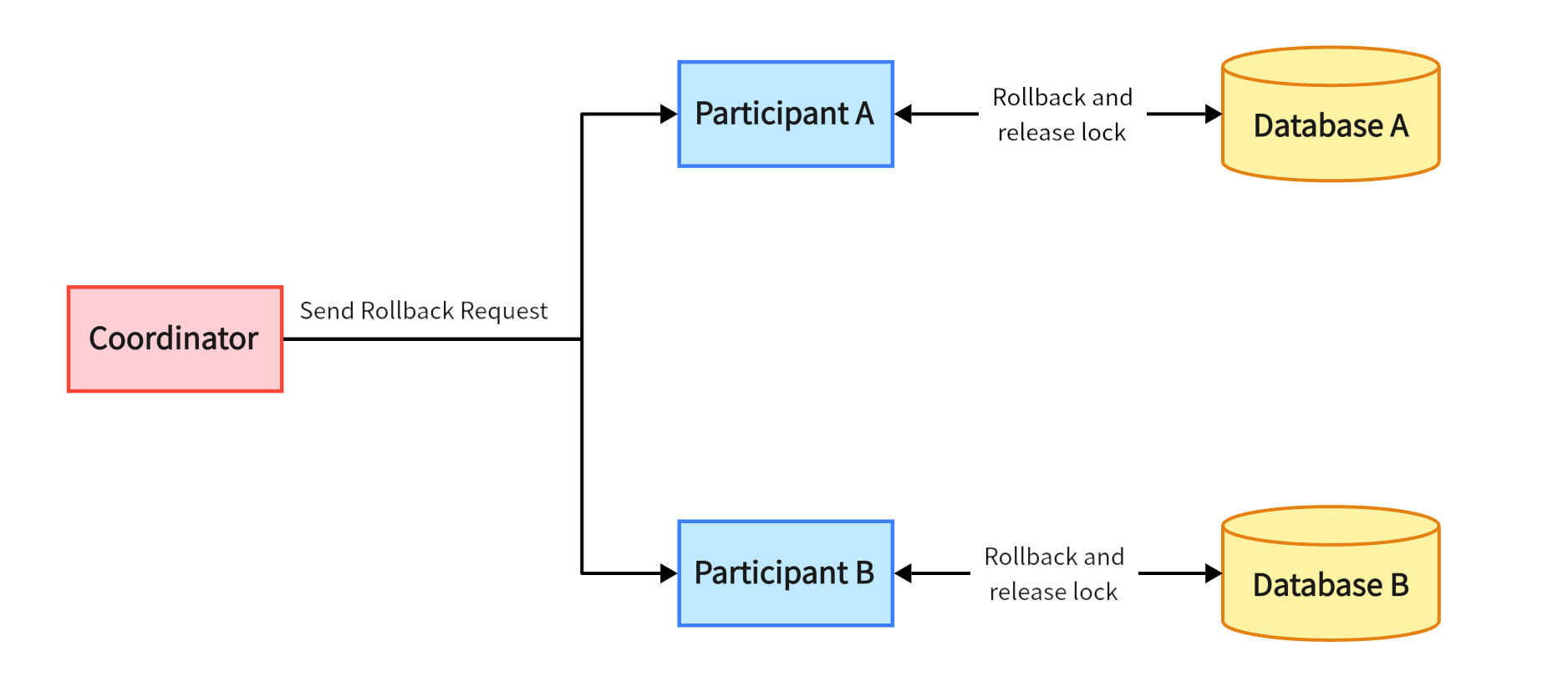
2PC Commit Phase - rollback
Defects
Performance issues.
During the execution process, all participating nodes are transaction blocking. After the participants lock the public resources, the third party has to be in a blocked state when accessing.
Single point of failure.
Once the coordinator fails, the participants will be blocked and unable to complete the transaction operation.
Data inconsistency.
In the second phase of processing, if a local network anomaly occurs after the transaction coordinator sends a
commitrequest to the participants, only some participants receive the request, resulting in inconsistent data in the entire distributed system.Uncertain status.
If the coordinator crashes after issuing a
commit, and the only participant who receives thiscommitalso crashes, then even if the latest coordinator is selected, the status of the transaction cannot be determined.
3PC
3PC is also known as: three-phase commit, which is an improvement on 2PC. In addition to the performance improvement, it also avoids infinite blocking caused by certain single point failures.
In 3PC, we use Prepare and Commit Before these two phases, add a new phase: CanCommit==, and add a timeout mechanism.
Algorithm principle
CanCommit
The coordinator initiates a distributed transaction.
The participant tries to obtain the database lock and checks whether it has the ability to complete the transaction.
If the participant believes that it can complete the transaction, it returns YES, otherwise it returns NO to the coordinator.
In this phase, the participant only tries to obtain the database lock, but does not hold the database lock all the time, so it will not cause long-term resource locking.
PreCommit
If the coordinator receives YES feedback from all participants, it will enter the PreCommit phase to pre-commit the transaction.
The coordinator sends a
PreCommitrequest to all participants.The participant starts to execute the transaction operation and undo and redo The information is recorded in the transaction log.
The participant sends an Ack back to the coordinator to indicate that it is ready to commit and wait for its next instruction.
At this time, the participant's transaction is still in an uncommitted state.
If the coordinator receives a No response from any participant in the CanCommit phase, or times out while waiting for the participant to return, the abnormal process is triggered and the entire distributed transaction will be interrupted.
The coordinator sends an
abortcommand to all participants.The participant abandons this transaction.
DoCommit
If the coordinator receives Acks from all participants, it enters the DoCommit phase to formally commit the transaction.
The coordinator sends a
DoCommitrequest to all participants.The participant starts to commit the transaction operation.
The participant returns after the submission is successful Ack to the coordinator.
If the coordinator receives a No response from any participant in the PreCommit phase, or times out while waiting for the participant to return, the abnormal process is triggered and the entire distributed transaction will be interrupted.
The coordinator sends an
abortcommand to all participants.The participant abandons this transaction.
Optimization compared to 2PC
Timeout mechanism.
3PC introduces a timeout mechanism for participants, which may occur in the
PreCommitandDoCommitphases.- Participants will abandon execution if a timeout occurs in the
PreCommitphase, and will execute the commit in theDoCommitphase. - The coordinator will send a rollback at any time when a timeout occurs.
This avoids the problem in 2PC that participants cannot release resources when they cannot communicate with the coordinator for a long time or the coordinator is down. That is, single point failure problem .
- Participants will abandon execution if a timeout occurs in the
Performance optimization.
3PC adds a
CanCommitstage, at which participants do not hold database locks. 3PC reduces the time participants hold locks.
Defect
Data consistency problem.
3PC still does not completely solve the problem of data inconsistency caused by local network problems.
TCC
TCC ( Try-Confirm-Cancel ) is also known as: compensation transaction. Its core idea is: for each operation, a corresponding confirmation and compensation must be registered. Unlike 2PC and 3PC, TCC introduces a transaction coordination service for scheduling.
Algorithm principle
Try stage
Check the business system and reserve resources.
Confirm stage
Confirm the execution of business operations.
Cancel stage
Cancel the execution of business operations.
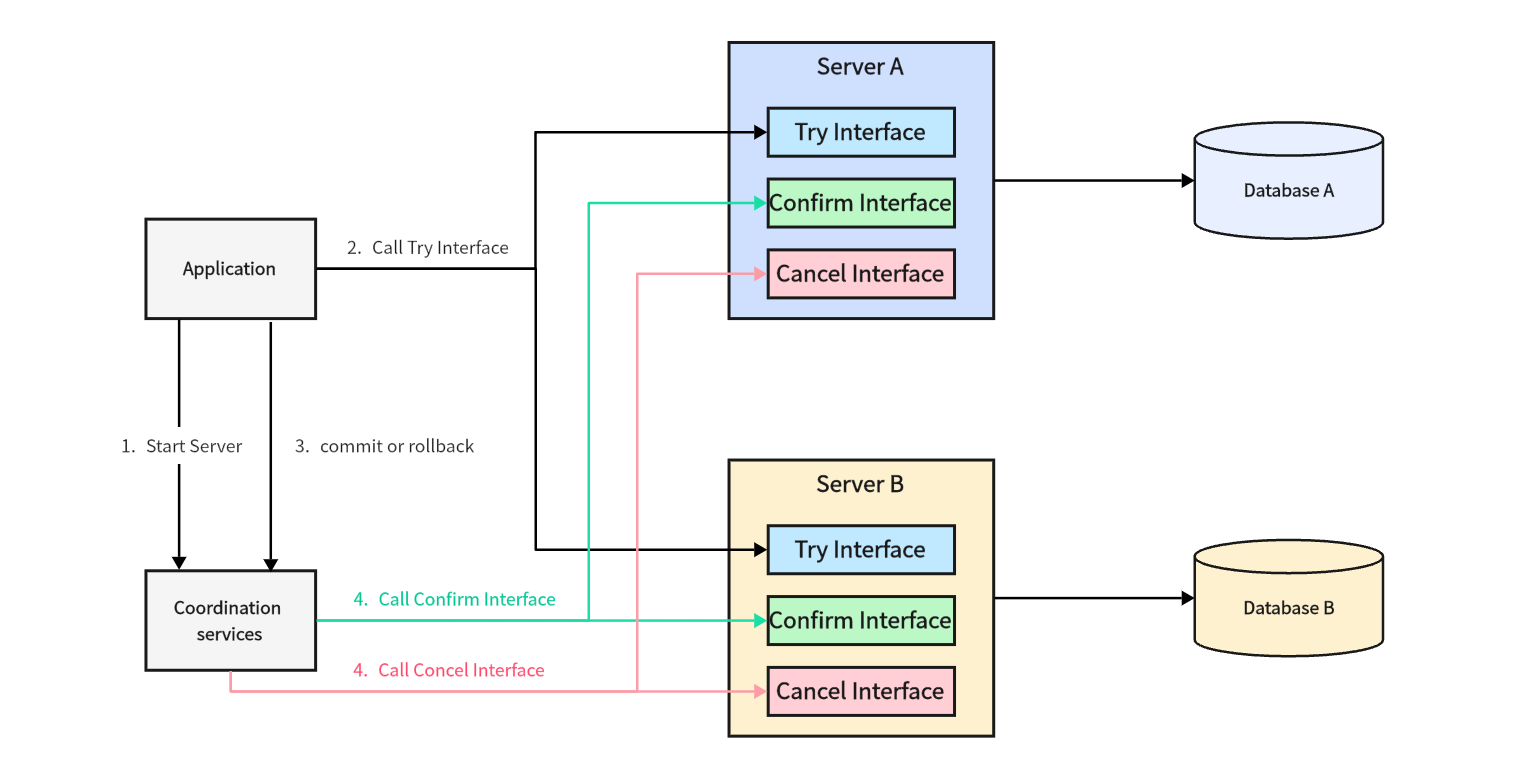
In most financial scenarios, TCC is used to ensure the consistency of distributed transactions. Because in this more rigorous business scenario, we need to have higher control over each business process.
Disadvantages
- Strong business intrusion.
The corresponding implementation of the three operations of Try, Confirm and Cancel must be implemented for each business logic.
- Difficult to implement.
Different rollback strategies need to be implemented according to different failure reasons ( for example: network failure, system failure, etc. ) .
Asynchronous
All the solutions introduced above are synchronous calling solutions. When the concurrency is particularly large, the performance is not ideal. We can use message queues to decouple the system and cache messages to achieve higher concurrency performance.
Algorithm principle
We divide distributed operations into upstream business and downstream business, and create a message management service.
The core idea is: there is a 2PC mechanism between the upstream business and the message management service to ensure data consistency. When the transaction is completed, the completed message will be put into the message queue. The downstream system consumes the message.
Disadvantages
- Complex business logic.
- Can only guarantee the final consistency of data.
Summary
In this article, a total of four distributed transaction consistency solutions are introduced, and their respective advantages and disadvantages are discussed.
2PC
The most basic solution model divides the submission of transactions into two stages: Prepare and Commit, and uses the coordinator to ensure the consistency of the status among all participants. However, due to the lack of a timeout mechanism, when the coordinator goes down, there may be problems such as infinite waiting of participants and inability to release resources.
3PC
On the basis of 2PC, a buffer stage is added to reduce the time that participants hold database locks, and a timeout mechanism is added to avoid the problem that resources cannot be released. However, the problem of data inconsistency is still not completely solved.
TCC
For each business, three interfaces, Try, Confirm and Cancel, are provided to the transaction coordination service, and the transaction coordination service will ensure data consistency. Doing so will lead to serious business intrusion of the code, but at the same time ensure that developers have more refined processing of business processes.
Asynchronous
The above three solutions are synchronous solutions and are not suitable for high concurrency scenarios. In the asynchronous solution, we use message queues to connect upstream and downstream businesses. A reliable message management service is used to ensure transaction consistency.
Contributors

Changelog
Copyright
Copyright Ownership:dingyuqi
License under:Attribution-NonCommercial-NoDerivatives 4.0 International (CC-BY-NC-ND-4.0)