Basic concepts and common problems related to Kafka
Kafka is currently the most mainstream distributed stream processing platform. It is widely used for its high throughput, persistence, horizontal scalability, support for stream data processing and other features.
There are three main application scenarios:
- Message system: Based on the functions of traditional message systems, such as system decoupling, traffic peak shaving, buffering, asynchronous communication, etc., Kafka also provides message order guarantee and back-tracing consumption functions that most message systems cannot provide.
- Storage system: Kafka will persist messages to disk and has a multi-copy mechanism.
- Stream processing platform: Kafka It not only provides a reliable data source for each popular stream processing platform, but also provides a complete stream processing library.
This article is just my personal notes on some basic concepts of Kafka and records of common problems in work. It is not a strict novice teaching, and I will not explain too much about the concepts in it. It is more suitable for people who already have a certain concept of Kafka to review and search and read.
You can view according to the content you are interested in:
Basic concepts
Producer
Producer, the party that sends messages. The producer is responsible for creating messages and then sending them to Kafka.
Consumer
Consumer, the party that receives messages. Consumers connect to Kafka and receive messages, and then perform related business logic processing.
Broker
Service proxy node. You can see a Kafka server.
Topic
Topic. Logical concept, convenient for classifying messages.
A Topic can span multiple Brokers.
Partition
Partition. There will be many Partitions under a Topic, but a Partition will only belong to one Topic. Under the same Topic, the messages stored in different Partitions are different.
The messages in the Partition are ordered, while the messages in the Topic are not guaranteed to be ordered.
Replica
Multi-copy mechanism. The replicas maintain a "one master and multiple slaves" relationship. The leader-Partition is responsible for reading and writing, and the follower-Partition is only responsible for synchronizing data.
AR
The set of all replicas in the Partition, including the leader itself.
ISR
The set of replicas that are synchronized with the leader to a certain extent.
OSR
The set of replicas that lag behind the leader too much.
AR = ISR + OSR, and under normal circumstances, there will be no replica synchronization status that lags too much, that is, AR = ISR.
ISR scaling
The process in which the leader kicks out the follower that lags too much from the ISR is also called ISR Scalability.
HW
HighWatermark abbreviation, that is, "high water mark". Identifies a specific offset. Consumers can only read messages before HW.
LEO
Log End Offset abbreviation. Identifies the offset of the next message to be written.
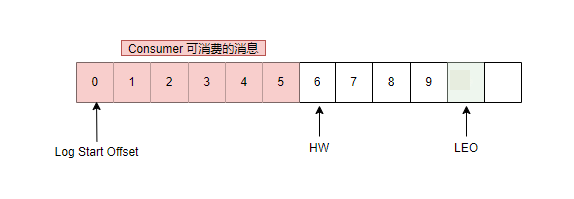
Description of various offsets in Partition The smallest LEO in ISR is the HW of Partition.
HW cannot be consumed by Consumers, and only messages before HW can be consumed. LEO is the offset of the next message to be written, not the offset of the last message.
When a message is written, LEO immediately +1, but HW is related to the synchronization of followers in ISR. Leader's HW = the smallest LEO of followers in ISR.
zookeeper
This is the installation of Kafka Necessary components of the cluster.
- Kafka uses zookeeper to manage metadata.
- Responsible for leader election and management.
Producer And Consumer
Producer
Producer in Kafka is thread-safe.
Sending messages to Kafka mainly involves the following steps:
Configure parameters to create an instance.
- bootstrap.servers
- key.serializer
- value.serializer
Build the message to be sent.
Send the message.
send ( )-> interceptor -> serializer -> partitioner -> broker.Close the instance.
Three modes of Producer sending messages
- fire-and-forget: Forget after sending. Do not expect any return, do not care whether the message actually arrives.
- sync: synchronous. Block and wait for Kafka's response.
- async: asynchronous.
In fact, this also corresponds to Kafka's three types of ACK.
1: The default success return. Indicates that the leader successfully receives the message.0: The producer does not wait for any return after sending the message. In this case, the transmission efficiency is the highest, but the message reliability is the lowest.-1: The Producer needs to wait for all followers in the ISR to confirm that they have received the message before sending an ACK to the leader, and the leader will commit. The message reliability is the highest.
Consumer
The Consumer in Kafka is not thread-safe because it is stateful.
Consumer Group
Consumer is responsible for subscribing to the Topic in Kafka and pulling messages from the subscribed Topic. Consumer has a logical grouping concept: Consumer Group, each consumer belongs to a consumer group. When a message is published to a topic, it will only be delivered to one consumer in each consumer group that subscribes to it.
Kafka supports the following consumption methods:
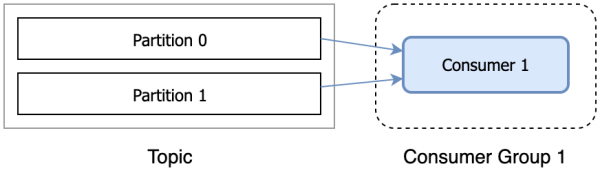
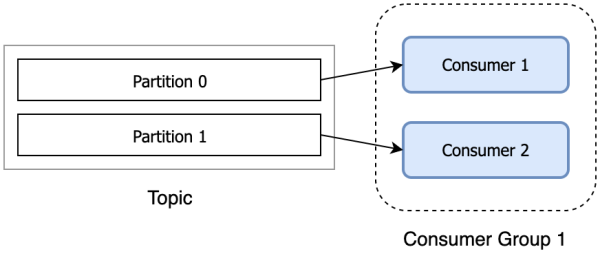
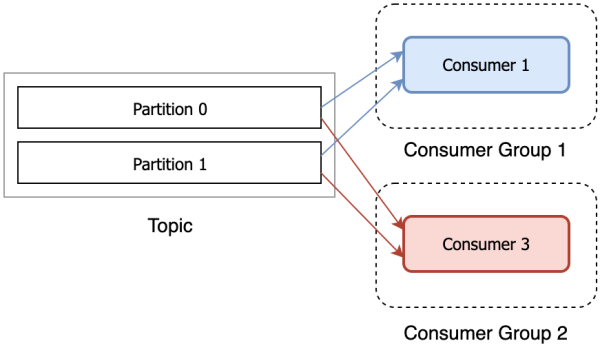
When the number of Consumers exceeds the number of Partitions, some Consumers will not be assigned any partitions and will not consume anything.
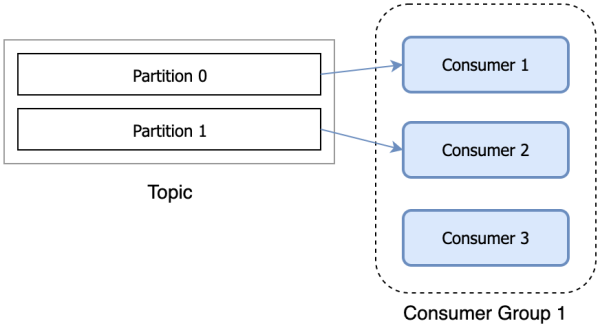
Consumption logic
Configure parameters to create an instance.
- bootstrap.servers
- group.id
- key.serializer
- value.serializer
Subscribe to Topic.
Pull messages and consume.
Submit offset.
Submit
x + 1Instead ofx.Shut down the instance.
Rebalance
Triggering scenario
- A new Consumer joins the Consumer Group.
- A Consumer goes offline.
- A Consumer voluntarily exits the Consumer Group.
- The number of partitions of any Topic subscribed by the Consumer Group changes.
Phase 1 FIND_COORDINATOR
Consumer needs to determine the Broker of the Group Coordinator corresponding to its Consumer Group and establish a connection with it.
If the Consumer has saved the Group Coordinator node information and the connection is normal, it will enter the next stage. If not, it will send a FindCoordinatorRequest to the node with the smallest cluster load.
Phase 2 JOIN_GROUP
Enter this stage after successfully finding the Group Coordinator corresponding to the Consumer Group.
In this stage, the Consumer will send a JoinGroupRequest to the Group Coordinator and process the response.
Elect the leader of the Consumer Group
If there is no Group Coordinator in the group leader, the first Consumer to join the Consumer Group becomes the leader.
If the leader leaves the Consumer Group, the first pair ( key, value ) in the HashMap of the Group Coordinator is taken as the leader. This method is almost random.
Election partition allocation strategy
//TODO
Phase 3 SYNC_GROUP
The leader implements specific allocation according to the partition allocation strategy elected in the second phase. Before this, the allocation plan must be synchronized to each Consumer, but it is not published directly by the leader itself, but through the Group Coordinator.
In this phase, the Consumer will send SyncGroupRequest to the Group Coordinator to synchronize the allocation plan.
Phase 4 HEARTBEAT
After entering this phase, all Consumers in the Consumer Group can operate normally. The heartbeat will be maintained between the Consumer and the Group Coordinator. If the heartbeat stops for too long, Rebalance will be triggered again.
Zero-Copy
Zero-Copy means copying data directly from disk files to network card devices without putting the device into user mode.
Suppose we need to show the files in the disk to the user. This means we need to copy the static files from the disk to a memory buf, and then pass this buf to the user through Socket. But in traditional copying, the file undergoes 4 copies in this process.
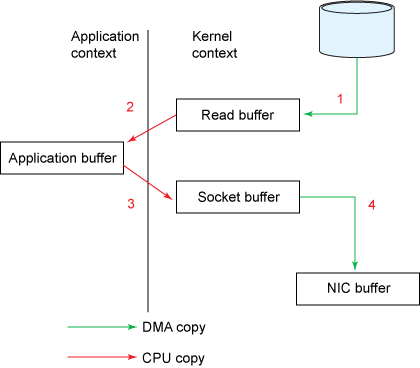
We can clearly see that the second and third copies are completely unnecessary. In fact, zero copy technology avoids those two copies.
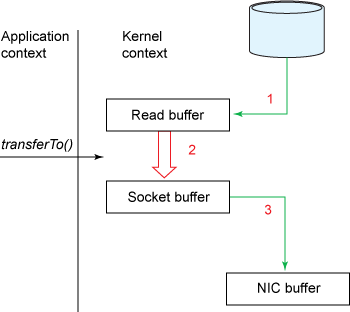
In Kafka, there are two places where Zero Copy is used:
- Index based on mmap.
- TransportLayer used for reading and writing log files.
Index based on mmap. Indexes are all based on MappedByteBuffer, which means that user mode and kernel mode share kernel mode data buffers. At this time, the data does not need to be copied to the user space. However, although mmap avoids unnecessary copying, it does not necessarily guarantee high performance. Under different operating systems, the cost of creating and destroying mmap may be different. High creation and destruction overhead will offset the performance advantage brought by Zero Copy. Due to this uncertainty, in Kafka, only the index applies mmap, and the core log does not use the mmap mechanism.
TransportLayer. TransportLayer is the interface of Kafka's transport layer. One of its implementation classes uses the transferTo method of FileChannel. This method uses sendfile to implement Zero Copy at the bottom. For Kafka, if the I/O channel uses ordinary PLAINTEXT, then Kafka can use the Zero Copy feature to directly send the data in the page cache to the Buffer of the network card to avoid multiple copies in the middle. On the contrary, if SSL is enabled for the I/O channel, then Kafka cannot use the Zero Copy feature.
Common Problem
Message Loss
1. Consumer Loss of Data
The situation in which consumers may cause data loss is: after the consumer obtains the message, it has not yet processed it, Kafka automatically submits the offset. At this time, Kafka thinks that the consumer has processed the message, but in fact, the consumer is just about to process the message. If the consumer crashes at this time, the message will be lost.
The main reason for the loss of messages caused by consumers is that Kafka automatically submits the offset before the message is processed. Then, as long as the automatic submission of offset is turned off, the consumer manually submits the offset after processing, the message will not be lost. However, you need to pay attention to the problem of repeated consumption at this time. For example, the consumer has just processed and has not submitted the offset, and it crashes at this time. At this time, the message will definitely be consumed again, which requires the consumer to ensure idempotence according to the actual situation.
2. Producer loses data
For data loss caused by producer data transmission, the main common situation is that the producer sends a message to Kafka, and the message is lost due to network and other reasons. This situation is also handled by setting acks=all on the Producer side. This parameter requires that after the leader receives the message, it needs to wait until all followers have synchronized the message before it considers the write successful. If this condition is not met, The producer will automatically retry continuously.
3. Kafka data loss
A common scenario is that a Kafka Broker crashes and then re-elects the leader of the Partition. If other followers happen to have some data that has not been synchronized at this time, and the leader crashes at this time, and then a follower is elected as the leader, data loss will occur.
So in summary, in order to avoid message loss, it is generally required to set the following 4 parameters:
- Set the
replication.factorparameter for the Topic: This value must be greater than 1, and each Partition must have at least 2 copies. - Set the
min.insync.replicasparameter on the Kafka server: This value must be greater than 1, which requires a leader to at least perceive that there is at least one follower that is still in contact with itself and has not fallen behind, so as to ensure that there is a follower that can run for the leader after the leader crashes. - Set
acks=allon the Producer side: This requires that each piece of data, The write is considered successful only after all replicas have been written. - Set
retries=MAXon the Producer side: This requires infinite retries if the write fails. I am stuck here.
After this configuration, at least on the Kafka Broker side, it can be guaranteed that when the Broker where the leader is located fails and the leader is switched, the data will not be lost.
Ensure message order
The following two points need to be considered:
- How to ensure the order of messages in Kafka.
- How to ensure the order of Consumer processing.
How to ensure the order of messages in Kafka
For Kafka, if we create a Topic, there are three Partitions by default. When the producer writes data, it can specify a key. For example, in the order Topic, we can specify the order id as the key. Then the data with the same order id will be distributed to the same Partition, and the data in this Partition must be in order. When the consumer takes data out of the Partition, There must be an order. By setting a key, we can first ensure that the messages are ordered inside Kafka.
How to ensure the order of consumer processing
For a Partition of a Topic, it can only be consumed by a consumer in the same group. If this consumer is still single-threaded, then as long as the messages are ordered inside MQ, the consumption can be guaranteed to be ordered. However, the single-thread throughput is too low. When processing a large number of MQ messages, we generally enable the multi-threaded consumption mechanism.
So how to ensure that the messages are processed sequentially between multiple threads? For multi-threaded consumption, we can pre-set N memory queues, and put data with the same key in the same memory queue. Then start N threads, and each thread consumes data from a memory queue. Of course, the message may not be processed after being placed in the memory queue. If the consumer crashes, all the data in the memory queue will be lost, which turns into the problem of how to ensure reliable transmission of messages mentioned above.
No duplicate consumption
This problem is actually equivalent to consumer idempotence.
When the producer sends each piece of data, add a globally unique id. We can use the database to ensure no duplicate consumption:
- Based on Redis. Check in Redis before consumption to see if it has been consumed before? If not, process it, and then write this id to Redis. If it has been consumed, ignore it.
- Based on the unique key of the database. Due to the constraint of the unique key, duplicate data insertion will only report an error, and will not cause dirty numbers in the database.
Why does Kafka not support read-write separation?
In Kafka, the operations of producers writing messages and consumers reading messages are all interacting with the leader replica, thus realizing a production and consumption model of master-write and master-read.
Kafka does not support master-write and slave-read, because master-write and slave-read have two obvious disadvantages:
- Data consistency problem. There will inevitably be a delay time window when data is transferred from the master node to the slave node, and this time window will cause data inconsistency between the master and slave nodes. At a certain moment, the value of data A in the master node and the slave node is X, and then the value of A in the master node is changed to Y. Then before this change is notified to the slave node, the value of data A read by the application in the slave node is not the latest Y, which causes data inconsistency.
- Delay problem. For components like Redis, the process of data from writing to the master node to synchronizing to the slave node needs to go through the stages of "network->master node memory->network->slave node memory", and the whole process will take a certain amount of time. In Kafka, master-slave synchronization will be more time-consuming than Redis. It needs to go through the stages of "network->master node memory->master node disk->network->slave node memory->slave node disk". For latency-sensitive applications, the master-write-slave-read function is not very applicable.
Summary
So far, this article has introduced the basic knowledge related to Kafka and the handling of common problems.
- Producer sends messages to Kafka, thread-safe.
- Consumer receives messages, non-thread-safe.
- Rebalance is triggered when the relationship between Consumer and Topic needs to be reallocated.
- Rebalance has 4 stages.
- Kafka uses zero-copy technology, reducing the conversion between user mode and kernel mode twice.
- You can set 4 parameters to ensure that Kafka messages are not lost.
- You can set id and Queue to ensure the order of messages.
- Redis and database unique key constraints can be used to avoid duplicate consumption.
- Kafka does not support read-write separation.
With subsequent learning, This article may be updated continuously.
References for this article
Contributors

Changelog
Copyright
Copyright Ownership:dingyuqi
License under:Attribution-NonCommercial-NoDerivatives 4.0 International (CC-BY-NC-ND-4.0)