How does Postgres manage memory? How to tune memory?
This document mainly records the learning content in the process of troubleshooting the problem of query interface timeout caused by excessive memory usage of PostgreSQL database during large-scale writes. It mainly focuses on memory management and learns the relevant core architecture of PostgreSQL.
PostgreSQL Process Structure
Main Process Potmaster
The main functions of the PostgreSQL database are concentrated in the Postmaster process, and the installation directory of the program is generally the bin directory. If you are not sure, You can use the command: which postgres to check.
Postmaster is the master control process of the entire database instance, responsible for starting and shutting down the database instance. The pg_ctl command we usually use is actually to run the Postmaster and postgres commands with appropriate parameters to start the database, but it is packaged for user convenience.
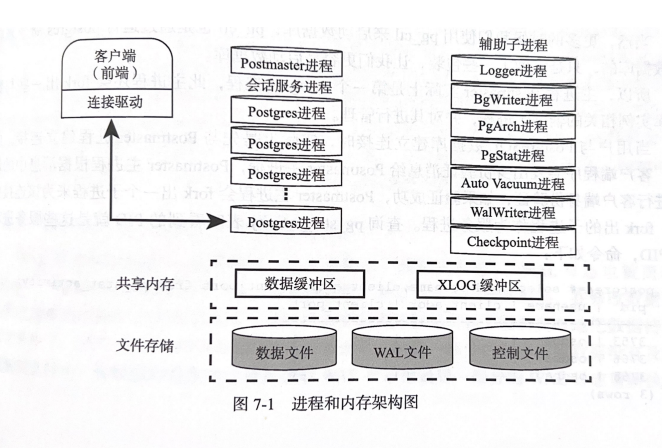
Postmaster is the first Postgres process of the database, and other auxiliary subprocesses are forked from Postmaster. When a user establishes a connection with PostgreSQL, it actually establishes a connection before the Postmaster process. At this time, the client program will send an authentication message to the Postmaster process. If the authentication is successful, Postmaster will fork a subprocess to serve the connection. The forked subprocess is called a service process, which can be viewed using the command:
SELECT pid, usename,client_addr, client_port FROM pg_stat_activity;When a service process has a problem, the Postmaster main process will automatically complete the system recovery. All service processes will be stopped during the recovery process. Then the consistency of the database is restored, and new connections can be accepted only after the restoration is completed.
Auxiliary Process
Logger System Log Process
In the postgresql.conf file, set the parameter logging_collect to: on, and the main process will start the Logger auxiliary process.
This auxiliary process will record the stderr output of the Postmaster main process, all service processes, and other auxiliary processes. The file size and retention time can be configured in the postgresql.conf file. When the file size or retention time limit is reached, the Logger will close the old log file and create a new log. If the signal for loading the configuration file: SIGHUP is collected, the configuration parameters log_directory and log_filename in the configuration file will be checked to see if they are the same as the configuration at that time. If they are not the same, the new configuration will be used.
BgWriter Background Writing Process
This auxiliary process is the process that writes dirty pages in the shared memory shared_buffers to the OS cache and then refreshes them to the disk. The refresh frequency of this process will directly affect the efficiency of reading and writing. It can be controlled by the relevant parameters prefixed with bgwriter_.
WalWriter Write Ahead Log Writer Process
WAL is the abbreviation of Write Ahead Log, which is Write Ahead Log, and is also referred to as xlog. WalWriter is the process of writing WAL logs. WAL logs are saved under pg_xlog.
Write Ahead Log records the modified operations to disk before modifying the data. The advantage is that when the actual data is updated later, it is not necessary to persist the data to the file in real time. If the machine crashes or the process exits abnormally in the middle, causing some dirty pages to not be refreshed to the file in time, after the database is restarted, the last part of the log can be read by re-executing the WAL log to restore the status.
PgArch Archive Process
WAL logs will be used in a circular manner, that is, the early WAL logs will be overwritten. The PgArch archive process will back up the WAL logs before they are overwritten. From After version 8.0, PostgreSQL uses PITR ( Point-In-Time-Recovery ) technology. That is, after a full backup of the database, this technology can be used to archive the WAL logs after the backup time point. The full backup of the database plus the subsequent WAL logs can be used to roll back the database to any time point after the full backup.
AutoVaccum Automatic Cleanup Process
In the PostgreSQL database, after the DELETE operation or other update operation on the table, the disk will not be released or updated immediately. Only a new row of data will be added, and the original data will be marked as "deleted". The old data will be deleted only when there are no concurrent transactions reading these old data.
The AutoVaccum process performs this kind of deletion work. There are many parameters in postgresql.conf that can specify the frequency and strategy of deletion, but the default is to perform automatic cyclic deletion, so it is called Auto.
PgStat Statistical Data Collection Process
This process mainly collects data statistics. The collected information is mainly used for cost estimation during query optimization. Information includes how many inserts, updates, deletes, disk reads and writes, and row reads were performed on a table and index. This information is collected in the system table pg_statistic.
PostgreSQL Memory Management
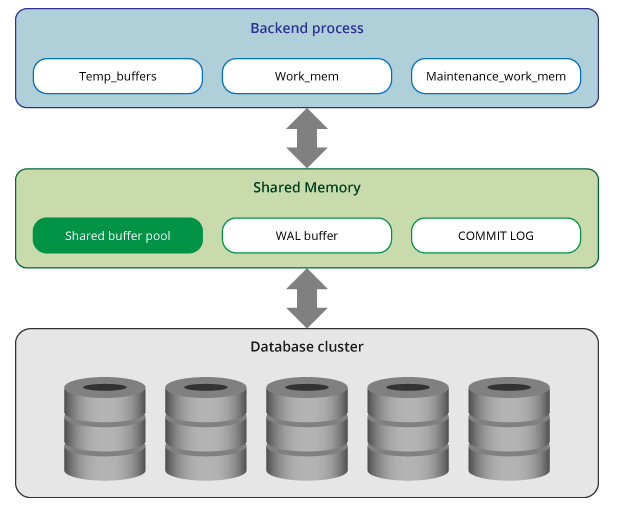
Postgres memory is divided into two main categories:
- Local storage space: allocated by each backend process for its own use.
- Shared storage space: shared by all processes in the PostgreSQL service.
Local Storage Space
In PostgreSQL, each backend process allocates local memory for query processing; each space is divided into subspaces, and the size of the subspace is fixed or variable.
All subspaces are as follows:
Work_mem
The executor uses this space to sort tuples by ORDER BY and DISTINCT operations. It also uses it through merge-join and hash-join. Operation to connect to the table.
Maintenance_work_mem
This parameter is used for some types of maintenance operations ( VACUUM, REINDEX ) .
VACUUM means to reclaim resources. Simply put, after executing the delete operation, we only mark the deleted records, but do not actually delete them physically, nor release space. Therefore, although these deleted records are deleted, other new records still cannot occupy their physical space. We call this space occupation HWM ( high water mark ) .
REINDEX rebuilds the index using the data stored in the index table, replacing the old copy of the index. The general reason is to recover from an index crash or to make index changes to take effect.
Temp_buffers
The executor uses this space to store some temporary tables. Generally keep the default value.
Shared Storage Space
The shared memory space is allocated by the PostgreSQL server at startup. This space is divided into several subspaces of fixed size.
Share Buffer Pool
PostgreSQL Load the pages in the table and index from the persistent storage into the shared buffer pool, and then operate on them directly.
WAL Buffer
PostgreSQL supports the WAL ( Write ahead log ) mechanism to ensure that data is not lost after a server failure. WAL data is actually the transaction log in PostgreSQL, and the WAL buffer is the buffer area before the WAL data is written to the persistent storage.
Commit Log
The commit log ( CLOG ) saves the status of all transactions and is part of the concurrency control mechanism. The commit log is allocated to shared memory and used throughout the transaction processing process.
PostgreSQL defines the following four transaction states:
- IN_PROGRESS
- COMMITTED
- ABORTED
- SUB-COMMITTED
PostgreSQL Memory Tuning
Shared_buffers
This parameter specifies the amount of memory used for shared memory buffers. The shared_buffers parameter determines how much memory is dedicated to the server cache data, which is equivalent to the SGA in the Oracle database. The default value of shared_buffers is usually 128 megabytes ( MB ) .
The default value for this parameter is very low because on some platforms ( such as old Solaris versions and SGI ) , having a larger value requires invasive actions such as recompiling the kernel. Even on modern Linux systems, the kernel will not allow shared_buffers to be set to more than 32 MB without adjusting the kernel settings first.
This mechanism has changed in PostgreSQL 9.4 and later, so the kernel settings will not have to be adjusted.
If there is a high load on the database server, setting a high value will improve performance.
If you have a dedicated DB server with 1 GB or more of RAM, a reasonable starting value for the shared_buffer configuration parameter is 25% of the memory in the system.
Default value shared_buffers = 128 MB. Changes require restarting the PostgreSQL server.
Tips for setting shared_buffers
- Under 2 GB of memory, set the value of shared_buffers to 20% of the total memory on the system.
- Under 32 GB of RAM, set the value of shared_buffers to 20% of the total memory on the system. For less than 32 GB of memory, set the value of shared_buffers to 25% of the total system memory.
- For more than 32 GB of memory, set the value of shared_buffers to 8 GB.
Work_mem
This parameter specifies the amount of memory used by internal sort operations and hash tables before writing to temporary disk files. If there is a lot of complex sorting happening, and you have enough memory, increasing the work_mem parameter allows PostgreSQL to do larger in-memory sorts, which will be faster than the disk-based equivalents.
Note that for complex queries, many sort or hash operations may be running in parallel. Each operation will be allowed to use as much memory as specified by this value before starting to write data to temporary files. There is a possibility that several sessions may be performing such operations at the same time. Therefore, the total memory used may be many times the value of the work_mem parameter.
Keep this in mind when choosing the right value. Sorting operations are used for ORDER BY, DISTINCT, and merge joins. Hash tables are used for hash joins, hash-based IN subquery processing, and hash-based aggregations.
Parameters log_temp_files can be used to log sort, hash, and temporary files, which is useful for determining whether the sort is overflowing to disk instead of in memory. You can use the EXPLAIN ANALYZE plan to check sorts that overflow to disk. For example, in the output of EXPLAIN ANALYZE, if you see a line like this: "Sort Method: external merge Disk: 7528kB", then at least 8 MB of work_mem will keep intermediate data in memory and improve query response time.
This parameter is not the total memory consumed, nor is it the maximum value of memory allocated to a process. Each HASH or sort operation in PostgreSQL will be allocated this much memory.
If there are M concurrent processes, each process has N HASH operations, the memory that needs to be allocated is M * N * work_mem, so don't set this too large, it is easy to OOM.
The default value is work_mem = 4 MB.
Tips for setting work_mem
- Start with a low value: 32-64 MB.
- Then look for "temporary files" in the log line.
- Set to 2-3 times the maximum temporary file size.
Maintenance_work_mem
This parameter specifies the maximum amount of memory used by maintenance operations such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY. Since a database session can only perform one of these operations at a time, and a PostgreSQL installation does not have many operations running simultaneously, it is safe to set maintenance_work_mem to a value significantly larger than work_mem.
Setting a larger value can improve the performance of vacuuming and restoring database dumps.
It is important to remember that when autovacuum is running, up to autovacuum_max_workers times the memory may be allocated, so be careful not to set the default value too high.
The default value of maintenance_work_mem is 64 MB.
Tips for setting maintenance_work_mem
- Set 10% of system memory, up to 1 GB.
- If you have vacuuming problems, you may want to set it higher.
Effective_cache_size
The effecve_cache_size should be set to an estimate of the memory available to the operating system and the database itself for disk caching. This is a guide to how much memory you expect to have available in the operating system and PostgreSQL buffer caches, not an allocation.
The PostgreSQL query planner uses this value to determine whether the plans it is considering will fit in RAM. If it is set too low, indexes may not be used to execute queries in the way you expect. Since most Unix systems are fairly aggressive at caching, at least 50% of the available RAM on a dedicated database server will be filled with cached data.
Tips for setting effecve_cache_size
- Set this value to the amount of file system cache available.
- If you don't know, you can set this value to 50% of the total system memory.
- The default value is effecve_cache_size = 4 GB.
Temp_buffers
This parameter sets the maximum number of temporary buffers used per database session. Session-local buffers are used only for accessing temporary tables. The setting of this parameter can be changed in individual sessions, But it can only be changed before the first use of a temporary table in a session.
PostgreSQL database uses this memory area to save temporary tables for each session, and these temporary tables will be cleared when the connection is closed.
The default value is temp_buffer = 8 MB.
How To View Each Configuration
First enter Postgres and use the following command to view the location of the conf file:
SELECT name,setting FROM pg_settings WHERE category='File Locations'; name | setting -------------------+--------------------------------------------------------- config_file | /usr/local/pgsql/data/postgresql.conf data_directory | /usr/local/pgsql/ external_pid_file | hba_file | /usr/local/pgsql/data/pg_hba.conf ident_file | /usr/local/pgsql/data/pg_ident.confView
postgresql.confandpostgresql.auto.confThis configuration file mainly contains some common settings and is considered the most important configuration file. However, starting from version 9.4, postgresql introduced a new configuration file
postgresql.auto.conf. When the same configuration exists, the system executes theauto.conffile first.In other words,
auto.confconfiguration file has higher priority thanconffile . It is worth noting that theauto.conffile must be modified using thealter systemcommand inpsql, whileconfcan be modified directly in a text editor.Modify parameters as required
alter system set shared_buffers=131072; alter system set max_worker_processes=104;Restart PosgreSQL
Performance Monitoring Tool
The monitoring tool I mainly use is Prometheus, and I can directly view the memory usage and I/O status of Docker on Grafana. However, the disadvantage of this method is that it can only see the overall memory usage, but cannot see the status of each task and the size of a single process and memory usage, so the pg_top tool is introduced.
sudo apt-get install pgtoppg_top -U postgres -d xxxxxx -h 192.168.xx.xx -p xxxx -W -s 1 -o res -I -cAll parameter meanings can be viewed at: pg_top parameters and content meanings
Caution
RES monitoring is not accurate. Only SELECT statements can be monitored, and INSERT statements RES are always 0 KB.
Summary
There is no total parameter that can directly limit the total memory usage of PostgreSQL, see: limiting-the-total-memory-usage-of-postgresql
However, you can adjust the corresponding parameters according to the characteristics of your query: such as multiple ORDER BY, multiple SORT, etc. to obtain better performance.
Contributors

Changelog
Copyright
Copyright Ownership:dingyuqi
License under:Attribution-NonCommercial-NoDerivatives 4.0 International (CC-BY-NC-ND-4.0)