"Consistent Hash" seems to be a confusing name, because the result of the hash function should be the same no matter where it is calculated, so why is there a consistency problem?
In fact, we proposed the concept of Consistent Hash to solve the problem in distributed storage. In distributed storage, different machines will store data of different objects, and we use hash functions to establish a mapping relationship between data and servers. So why is there "inconsistency"?
Now we need to store 10 data D1,D2,…,D10 in 3 machine nodes ( M0,M1,M2 ) . We can certainly use a mapping table to maintain the mapping relationship between data and machines, but that means we need to store an additional table and have to maintain it constantly. Even this table may not be able to store as the data increases. Then we naturally think of using a Hash function to calculate the mapping between data and machine nodes, so we have the following formula:
m=hash(o)modn
Where o is the name of the data object, n is the number of machines, and m is the machine node number where the storage object is calculated.
According to this formula, we can easily get the following mapping:
Machine number
Data
0
D3,D6,D9
1
D1,D4,D7,D10
2
D2,D5,D8
If we add a machine at this time, After n=4, the mapping can be recalculated:
Machine number
Data
0
D4,D8
1
D1,D5,D9
2
D2,D6,D10
3
D3,D7
Obviously, except for D1andD2, which have not changed the machine node, all other data have changed the storage machine. This means that when a machine node is added to the storage cluster, a large amount of data migration will occur, which undoubtedly adds a lot of pressure to the network and disk, and may even cause the database to crash in severe cases.
So the consistency of Hash does not mean that the results of repeated calculations of the Hash function are inconsistent, but that this calculation leads to data migration. So is it possible for us to reduce this data migration? Yes, Consistency Hash Algorithm can ensure that when machine nodes are increased or decreased, data migration between nodes is limited to two nodes, Without causing global network problems.
The entire algorithm mainly transfers the hash value space to a ring-shaped virtual space, and then maps the machine nodes and data. Let's take a look at the implementation process based on the example of data and machine node mapping mentioned above:
Create a hash ring Unlike general hash functions that map data to a linear space, we consider mapping the hash value space into a virtual ring space. If the value of the entire hash space is: 0∼232−1, then we arrange it clockwise so that the last node 232−1 overlaps at the starting position 0.
Ring Hash Space
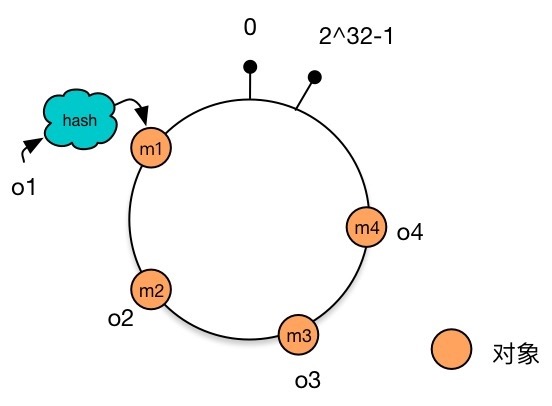
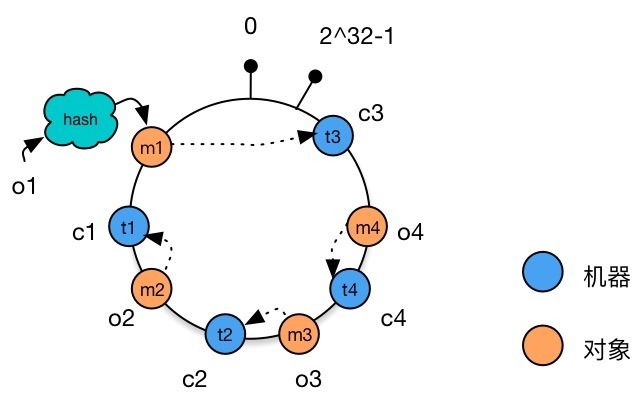
Map data to the Hash ring Assume that there are 4 data objects o1,o2,o3,o4, calculate the Hash value for each of them, and get the result m1,m2,m3,m4. Place these four results on the Hash ring.
Data objects mapped to the Hash ring
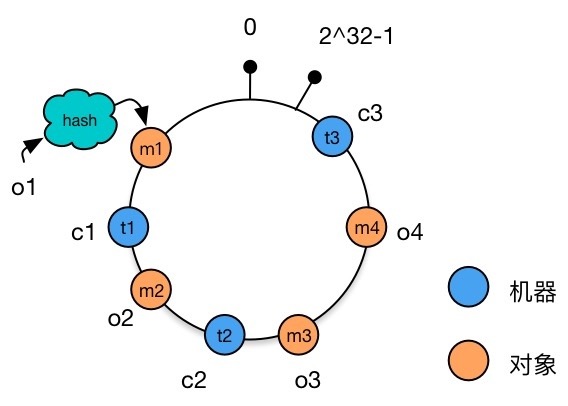
Map the server to the Hash ring Perform Hash calculation on the IP addresses of the 3 servers c1,c2,c3, and perform 232 modulo on the Hash value to get an integer t1,t2,t3 with a value between 0∼232−1. Map the integer after modulo on the Hash ring.
Mapping machine nodes to the Hash ring
Selecting machine nodes for data storage Each data object selects the machine closest to it in a clockwise direction for storage.
Data object selects machine node
The above has completed the calculation process of the entire Consistent Hash Algorithm. Next, let's take a look at the two scenarios mentioned at the beginning of the article: what changes will occur in the mapping between data and machines in adding machine nodes and deleting machine nodes.
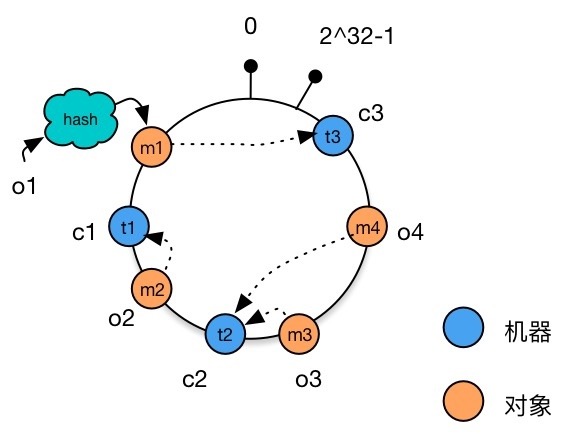
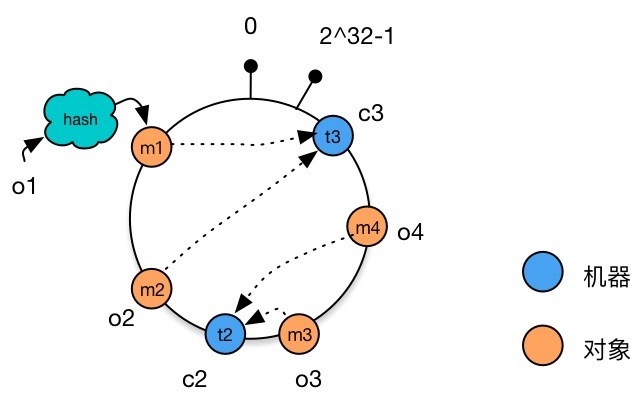
Now add a machine c4, and get the integer t4 after taking the Hash value modulo, and add it to the Hash ring.
Hash ring after adding machine nodes
It can be seen that unlike the situation at the beginning of the article where a large amount of data needs to change the machine node, now we only need to change a data object o4, and remove it from t3 is reallocated to t4.
Similarly, if we reduce a machine c1, after reallocating the machines, we find that only object o2 is reallocated to c3, and other data does not need to be changed.
This is a problem that consistent hashing can easily encounter. Generally speaking, we hope that data is evenly distributed on all machines, including after adding or removing machines. But observing the example of [adding nodes](/article/vpa4ql0t/#Adding machine nodes ) mentioned earlier, after adding machine c4, it only shares the pressure of c2. We can imagine that if we add node c5 again, unfortunately the hash value of the new node falls between t4 and t2 again, Then the newly added nodes cannot be assigned any data. It can be seen that adding machine nodes may not necessarily reduce the pressure of data load.
So how to solve it?
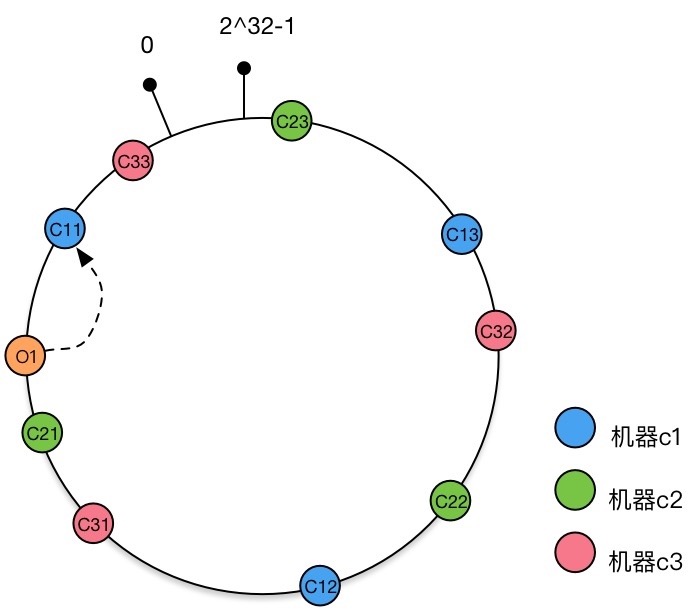
Solution: Virtual Node
Let's use the above example: For machines c1,c2,c3, in addition to being directly mapped to the Hash ring to form three nodes, each node also has two additional virtual nodes. The more virtual nodes there are, the more evenly the data is distributed on the machine.
After adding virtual nodes to the Hash ring
You can understand that we have added another layer of mapping from virtual machine nodes to actual machine nodes.
The Consistent Hash Algorithm solves the problem that when machines are added or reduced in a distributed environment, simple modulus operations cannot obtain a high hit rate.
Through the use of virtual nodes, the Consistent Hash Algorithm can evenly share the load of the machine, making this algorithm more realistic.