In the scenario of big data, we all know that when the number of single tables reaches 20 million or 2 GB, it is necessary to shard the database and table. However, after all data is sharded according to the specified sharding key, a new problem will arise: How to query non-sharding key? Of course, we can quickly think of a violent method, which is to use multiple threads to search all partitions at the same time, and then merge and summarize the results of each thread. But obviously this solution is very inefficient.
Can we directly determine which partition this data is in from the non-sharding key? The answer is: Yes. This article will introduce one of the methods: Gene method.
Requirement scenario
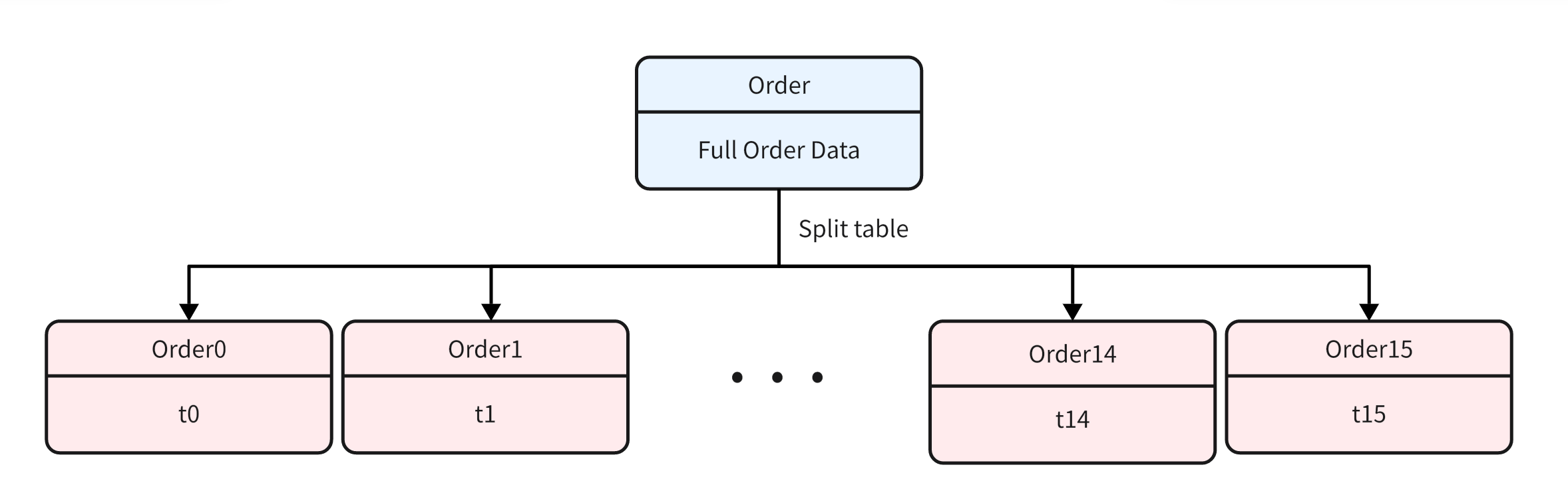
Suppose an e-commerce system, we currently have a large amount of order information that needs to be stored in the order table ( Order ) :
OrderId
UserId
OrderDetails
Order ID ( generated by snowflake )
User ID
Order details
Order table ( Order )
Now consider such a query requirement:
Query order details based on OrderId.
Query all orders of the user based on UserId.
Require database load balancing to avoid overload of a single database/single table.
Suppose we now need to divide the order table into 16 tables ( t0,t1,…,t15 ) .
Obviously, in the e-commerce scenario, most of our scenarios are to query the information corresponding to a certain UserId, such as: users view their own order records. So our first choice is to use UserId as the sharding key for Hash partitioning.
When we need to find all orders of UserId = 2846741676215238657, we only need to perform a modulo 16 operation on UserId to know the partition where all the order information of the user is located. 2846741676215238657 mod 16 = 7, so we can directly execute the following SQL in t7 to retrieve all order data.
SELECT OrderId FROM Order_7 WHERE UserId = '2846741676215238657';
After sharding with UserId as the sharding key
Data skew
In the actual production environment, the sharding key must be selected carefully, Because inappropriate sharding keys are likely to cause data skew in the sharded tables, that is, some tables have too much data and some have too little.
Here we use UserId. Assuming that all users are ordinary users, the number of purchases by each person will not differ by orders of magnitude. However, if we use "seller ID", the direct sales gap between each store may be several orders of magnitude, which may lead to serious data skew.
Through the modulo sharding of UserId, we have evenly distributed the order data into 16 tables. All orders for the same UserId are in the same table. The current solution has met 2 of the 3 requirements proposed at the beginning of this article. However, when we tried to query order details based on OrderId, we found that we could not know which partition a certain OrderId is in. We can only traverse 16 partitions until we find the specified OrderId. Obviously, this method is extremely inefficient.
At this time, we naturally think: If we query the order details based on OrderId It can directly know the partition table number where it is located. This involves the algorithm introduced next: Gene method. We implant the fragment of UserId into OrderId as a gene factor, so as to directly obtain the partition calculated with UserId as the partition key based on OrderId.
The gene method is based on a characteristic of binary: for a positive integer x and n, the result of taking the modulus 2n is equivalent to retaining the lower n bits of the binary representation of x and ignoring the higher bits.
xmod2n=x&(2n−1)
Assume x=29, which is 11101 in binary, and n=3. The lower n bits of x are represented in binary as: 101 ( decimal 5 ) . And 29 mod 8 = 5, which is exactly the same as the lower 3 The binary representation of the bits is the same.
So we can know that when the lower n bits in the binary representation of two values are the same, the modulo result of 2n is also the same. So when we use UserId to divide the data into 16 tables, the partition number of each UserId is actually the binary of its lower 4 bits ( log(16,2)=4 ) .
Based on the above theoretical basis, we now use the gene method to generate the OrderId we need, so that it can calculate the sharding information of UserId by itself.
Generate a unique ID.
Use the snowflake algorithm ( snowflake ) to generate a 64-bit distributed unique ID.
Calculate the sharding gene.
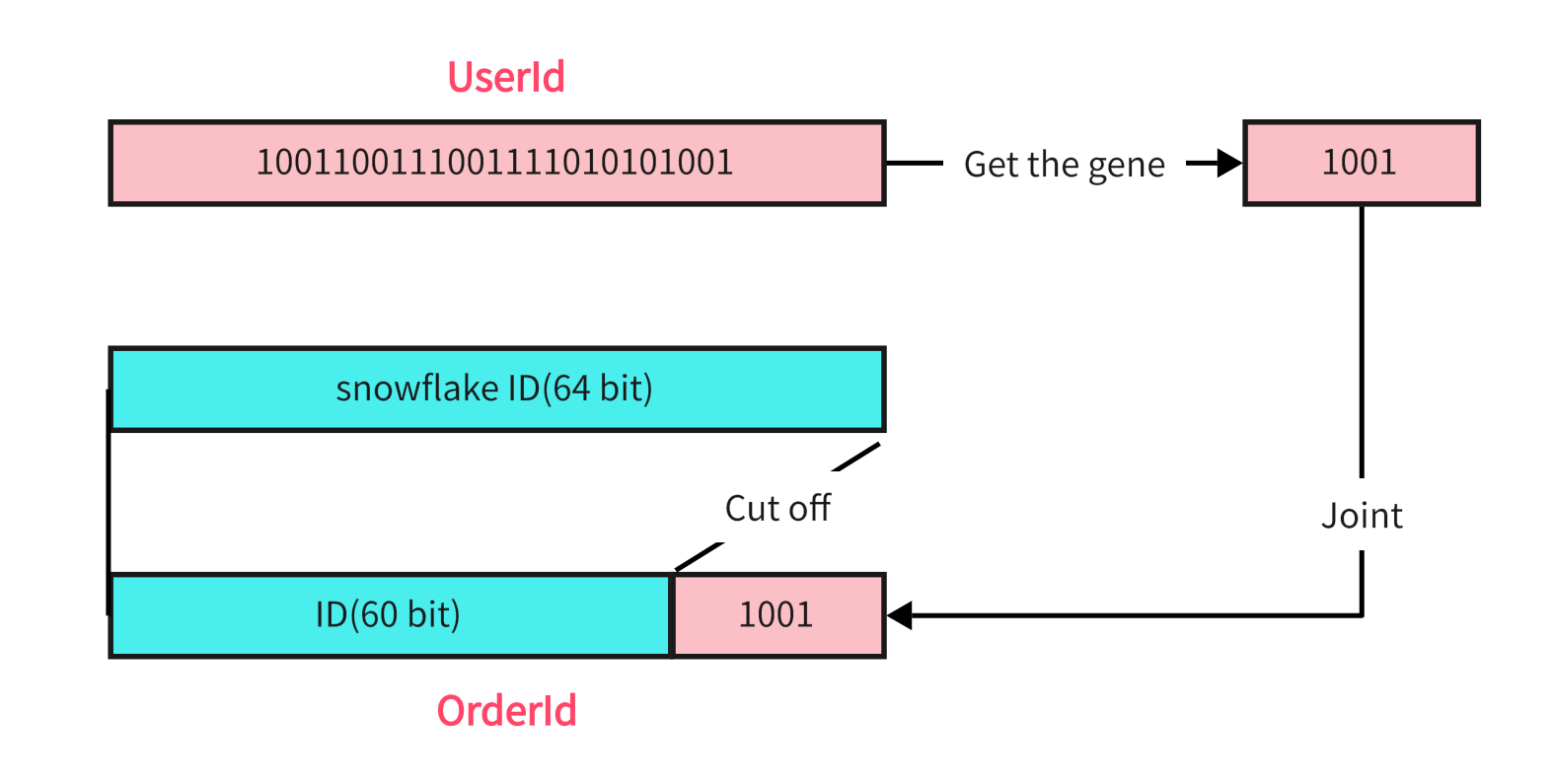
The sharding key is UserId, which is divided into 16 tables in total, so the sharding gene is the lower 4 bits of UserId. For example The binary low 4 bits of 2846741676215238657 are 1001, so its sharding gene is 1001. 3. Replace the low bits of the ID generated by the snowflake algorithm with the sharding gene.
Directly change the last four bits of the ID generated by snowflake to the sharding gene.
Generate OrderId by Genetic Method
The generated OrderId can ensure that when UserId is the same, OrderId will also be assigned to the same partition because its low bits are replaced with the same binary.
Duplicate IDs may appear
This gene replacement method cannot guarantee that IDs will not be repeated in extreme cases. Because if the same user creates 2 orders within one millisecond, the high bits of the ID generated by the snowflake algorithm are the same, and only the low bits differ by 1. However, in the gene replacement method, we replace the low bits of the two IDs with the same The fixed lower bits of UserId. This will cause the two IDs to become exactly the same.
This phenomenon is very extreme and almost impossible to occur under manual operation, but it does not rule out the possibility of this situation when the script is brushing orders.
In order to avoid the problem of repeated OrderId, we can also change the "replacement method" to the "splicing method". When constructing OrderId, directly splice the shard gene behind the generated ID, that is, OrderId = string ( snowflakeId + UserId ).
But this may cause the length of the ID to be very large. So we can also only splice the last 4 or 6 digits of UserId. In fact, Taobao's order number is generated in this way. The last 6 digits of the orders of the same user are the same. This means that Taobao divides it into 26=64 partitions.
The gene splicing method is based on decimal string splicing, while the gene replacement method is based on binary.
This article mainly introduces the gene method algorithm to solve the query optimization problem of non-sharding keys in the case of sharding. The gene method is divided into:
Gene replacement method
Gene splicing method Among them, the replacement method has the risk of ID duplication, while the splicing method can solve this problem well.
Further reading
When sharding, we can use the gene method to divide the data into a specified number of partitions. However, if the amount of data continues to grow and the original number of shards becomes insufficient to support the business, we may face the situation of increasing the number of shards.
The increase in the number of partitions means that the original partitioning according to the Hash modulus operation will change, which may involve a large amount of data migration. Data migration not only consumes resources, but also may cause system unavailability and increase additional network pressure. For this problem, we can solve it through the consistent Hash algorithm .