时序的 GFD 发掘
时序的 GFD 发掘 ( SEQUENTIAL GFD DISCOVERY )
我们将时间顺序的 GFD 发掘算法记作:SeqDisGFD。
这里面包含两个问题:
- SeqDis:给定 , 和 ,发现一个 k-bounded 的,具备 频繁的 GFDs 集合 。
- SeqCover:给定 ,如何计算它的一个覆盖 。
SeqDis
如果使用暴力枚举算法,首先根据传统图挖掘算法枚举出图 中所有频繁模式 ,然后通过增加属性来生成 GFDs。但是这种枚举 k-bounded GFDs 的方法在图 非常大的时候代价很大。
为了降低代价,SeqDis 算法将这两个步骤合并为一个,可以尽早地淘汰不感兴趣的 GFDs。
算法在 次迭代中运行。对于每个迭代 ,发现并存储所有的大小为 ( 有 条边 ) 且 频繁的最小 GFDs 在 集合中。在最初的迭代中,初始化一个 GFD 生成树 ,存储只包含单点的模式的频繁 GFDs。之后通过两个方向的扩展来扩展这个树:
- 垂直扩展:扩展模式 。
- 水平扩展:生成依赖 。
每次迭代 ,SeqDis 生成并证实 GFD 的候选项,并填充在树 的第 层。具体的操作为下面的两个步骤:
模式证实。
SeqDis 算法先进行垂直扩展。在 的第 层生成一个新的图模式。而每个图模式 都是由第 层的模式 通过扩展一条边 ( 或者一条边和一个新点 ) 得到的。然后通过模式匹配找到第 层所有模式的匹配。
GFD 验证。
算法随后进行水平扩展,将一组属性与 的第 层上新验证的图形模式关联起来,以生成一组 GFD 候选项。对于每一组候选项,执行 GFD 验证去找到 中的 GFDs,即第 层上满足 ,并且是频繁的,并且是最小的 GFD。验证过程一致持续到第 层的模式相关的所有的 GFD 候选项都被验证过。
这两个步骤不断迭代知道没有新的 GFDs 可以被生成,或者所有的 k-bouned GFDs 都被遍历过。
接下来详细介绍垂直扩展和水平扩展,算法的核心就是如何维持用来保存 GFD 候选项的生成树。
生成树
树 控制着 GFD 候选项的迭代。
每个在 的第 层的点 都存储着一个元组 。其中:
- 是一个拥有 个边的图模式。
- 是一个向量,每个条目 存储着一个以属性 为根的属性树。此时, 是 或者 ,其中 ,且 是 中的属性, 是 中的常量。
每个第 层的点的 是一个属性集合 ,使得 是一个 GFD 的候选项。对于一个属性 来说,如果 ,则 中有一个边 。
每个点 拥有一个边 连接到另一个点 如果 是由 扩展了一条单边形成的。
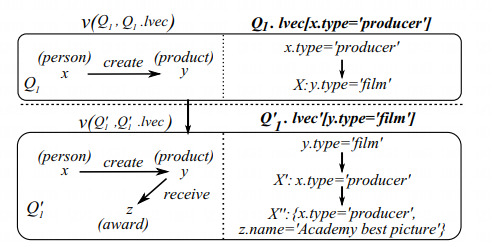
上图就是一棵 GFD 生成树 ,展示了前文中提到过的两个 GFD,分别是:
- GFD 。
- GFD 。
该生成树就只有两个节点,第一层的节点存储了 ,其中 是节点左边展示的图模式, 则是一个以 为根的树,相当于将 的函数依赖存储到一棵树。第二层的节点存储了 ,而 以 为根节点。
因为 是由 扩展一个属性得来的,即 ,所以 和 之间存在一条边。又因为 是通过给 增加一条 的边得到的,所以 到 有一条边。
注
对于第 层的 ,长度 最大为 ,其中 由 中的属性组成。
GFD 扩展
生成树 通过不断执行下面的两个原子操作来生成新的 GFD 候选项。
垂直扩展 ( )
垂直扩展操作 会在第 层通过在第 层的 的基础上增加一条边 来生成新的点 。它通过增加边 到 ,使得 在垂直方向上扩展。
显然 新增了一种图模式到 ,当 。对于第 层的每一个 GFD 来说,它通过增加一条边到 来生成模式 。例如图 3.1 中 进行垂直扩展,增加边 从而得到 。
水平扩展 ( $HSpawn )
水平扩展通过属性和约束来生成字段。具体来说, 在 中的第 层,字段树的第 层执行。例如图 3.1 中 就是发生在第 2 层的新图模式上。 通过增加 将 的 扩展到 的 。
剪枝
- 当验证 时,水平扩展终止。
- 当 时,垂直扩展终止。
这两条策略可以保证 GFDs 发现在实际应用时的可行性。
引理 4
对于一个支持度高于 的 GFDs 覆盖集 :
- 不包含任何的平凡 GFD。
- 对于任意的 ,如果 ,则 不包含 如果 。
- 如果一个 GFD 满足支持度 ,则 不包含 如果 。
